


Generative AI, GPT, and Large Language Models (LLM) have the potential to alter or disrupt just about every knowledge worker role in every market. In a recent 60 Minutes, Sundar Pichai claimed that ”This is going to impact every product across every company.”
Google is adding generative AI to their ads service. Venture capitalists don’t want to hear about blockchain or cryptocurrency anymore; they want to hear how startups are using AI and LLMs. Software vendors are generating code with GPT and other LLMs, and the list goes on. I will add data modeling to the list and share how GPT is changing data modeling.
What is GPT?
GPT, or Generative Pre-trained Transformer, is a series of natural language processing (NLP) models developed by OpenAI. It’s a generative AI language model, meaning it can produce new, coherent text based on the input or prompt it receives. The core architecture of GPT is based on the Transformer architecture, a type of neural network introduced by Vaswani et al. in a 2017 paper titled "Attention is All You Need."
GPT is pre-trained on a massive corpus of text data, which allows it to learn the structure and nuances of human language, predict the next word in a sentence, and capture complex language patterns and relationships. While the latest version, GPT-4, has demonstrated some impressive capabilities in numerous natural language processing (NLP) tasks, to get the most accurate results from GPT, it must be fine-tuned for the specific task, such as text summarization, translation, domain-specific narratives, question-answering, and data modeling.
The fine-tuning process involves training the model with domain-specific data aligned to the target task. So, fine-tuning GPT enables the language model to adapt to a specific domain or task, such as data modeling or query generation, leading to more accurate results. Now, this is getting more interesting. In short, the quality of the generated text is directly related to the quality of the fine-tuning process.
3 ways GPT is changing data modeling
Modeling for self-service analytics
Historically, when creating data models designed for self-service analytics, analytics engineers and data modelers looked to make it easy for non-technical users to understand the data model. They aimed to make it simple to get insights from the data, and easy to find metrics, measures, qualifiers, and attributes. However, this often entails making compromises like pre-aggregating the measures, renaming data for non-technical users, removing relationships, and flattening the data model. Even with these concessions, these data models may not achieve the lofty goals of self-service analytics.
You may be asking, “With GPT’s ability to generate SQL, can’t modelers just remove these compromises and let GPT generate the required query?” Not quite; recall that GPT needs to be fine-tuned to the specific task to reduce errors. Currently, GPT, and for that matter, any other LLM, will not understand the complexity of joins, aggregates, join-optimization, and mapping business language to technical jargon. GPT will need to be fine-tuned with the domain-specific labeled data. Although GPT may be able to understand and query a one-big-table (OBT) model, those compromises still exist, and there are many more reasons to avoid the one-big-table (OBT) approach.
Figure 1 - GPT Integration Architecture
This is where ThoughtSpot Sage, our AI-Powered search experience, comes into play by enabling Natural Language Queries (NLQ) on all of your business data. ThoughtSpot Sage combines the power of GPT’s natural language processing and generative AI with the accuracy of our patented search technology to deliver trusted and accurate results.So, business users are confident when they ask, “What are my top products by region this year compared to last year?”
Semantic layers are tools for defining precise definitions of measures, qualifiers, groupings, and of course, their description or meaning. Semantic layers will also begin to use GPT in much the same way. With the addition of GPT, those formal and precise definitions can be used to generate business-friendly narratives and descriptions and still remain consistent with the semantic layer.
Recognition of entities, relationships, and classifications
GPT uses unsupervised learning to analyze and understand text data. It does not have a specific built-in capability to identify entities and relationships, yet these capabilities seem to have emerged. The emergence of capabilities is one of the most exciting aspects of LLMs. Amit Prakash, ThoughtSpot Co-founder and CTO, dives deeper into this topic in his blog, Emergent properties of Large Language Models.
GPT can be further fine-tuned to identify entities and relationships for a specific domain by combining with other algorithms, such as Named Entity Recognition (NER) and Dependency Parsing. However, in the example below, I’ve used the standard GPT-3 model to identify the entities and relationships.
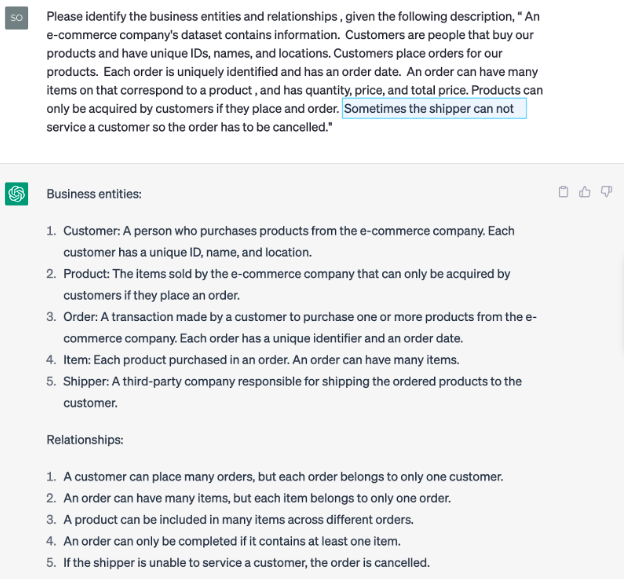
Figure 2 - Entity recognition example
Based on the text in the prompt, GPT has identified and described the business entities and how they are related. It is worth noting the Shipper entity is only mentioned in passing in the text. While other entities have more details, descriptions, and relationships, GPT added Shipper to the list of entities and relationships. What’s important is that we have identified a new and potentially critical entity that may have slipped by an unsuspecting data modeler.
Improved communication
Capturing the essential concepts of a business process is crucial to creating a quality data model, and GPT has the capability to make business knowledge accessible and understandable. These essential concepts are initially captured in the conceptual modeling phase, which often requires multiple in-depth discussions with subject matter experts, business stakeholders, and front-line operations.
Data modelers can use GPT to summarize a vast number of documents to discover the essential concepts, as well as validate stakeholder perspectives and assumptions.
With data modeling, it’s critical to communicate with business users how they best absorb the material. That usually means no Entity Relationship Diagrams (ERD) with many rectangles, lines, arrows, and crows-feet. GPT gives data modelers the ability to generate narratives and summaries in the voice of the business user. As a modeler, that may take me days or a week to create; GPT can do it in seconds.
As GPT becomes even more advanced and more products utilize GPT, a new collaboration and trust model between humans and machines is emerging. Utilizing GPT in a “better together” mindset reduces the time required for conceptual modeling, produces higher-quality data models, and improves stakeholder communication.
💡 Want to explore data modeling in more depth? Conceptual vs Logical vs Physical Data Models: What’s the Difference?
Start Getting Better Insights
What’s the overall impact?
With the current revitalization and modernization underway in the data modeling field, the addition of GPT is a welcomed improvement. Integrating GPT into data modeling workflows and tools can:
Increase the speed of data modeling
Facilitate the integration of self-service analytics into mainstream practices
Enhance the clarity of semantic layers
Bridge the gap that often exists between technical data modelers and business-oriented end-users
Can data modeling expect to face further impacts, setbacks, or misdirections in the future? Of course, but that is the cost of innovation. Despite the ever-accelerating rate of change, data modeling has demonstrated resilience over the years, creating new capabilities and adapting to evolving technologies, methodologies, and data architectures, and delivering value to businesses and stakeholders. From my perspective, I see every indication that the positive trend will continue. As data modelers, we should continue our agile journey and embrace the inevitable change ahead.
Modern data stack technologies will quickly integrate with GPT and other LLMs. As they do, my advice to you is to stay informed, look beyond the shiny new objects, evaluate the products for real business value, and look for secure, transparent trustworthy solutions that provide true innovation.
See how ThoughtSpot is integrating with GPT to enhance data modeling capabilities—watch Beyond 2023 on demand. Or, start your free-trial today to get hands-on experience with ThoughtSpot Sage.



