


Remember when handling billions of data points required hundreds of engineers and years of development? During my time at Google in the mid-2000s, we dealt with tens of billions of ad impressions daily, training machine learning models on years of historic data to rank ads in real time. The whole system was an amazing feat of engineering—no system out there could handle this scale.
Today, you can achieve the same scale in your enterprise through rapid innovation in cloud data technology. What once took massive engineering teams is now accessible through the modern data stack: a collection of cloud-native tools that work together to collect, process, store, and analyze data at any scale.
What is the modern data stack?
The modern data stack is a collection of cloud-native tools that work together seamlessly: Ingestion tools pull data from sources, cloud warehouses store it, transformation engines prepare it, analytics platforms surface insights, and activation tools push those insights into action.
What makes a modern data stack modern is how these technologies diverge from the traditional architecture of legacy data stacks. Some of the core differences include:
|
Dimension |
Legacy Data Stack |
Modern Data Stack |
|
Architecture |
On-premises monoliths |
Cloud-native, elastic infrastructure |
|
Data processing |
ETL into rigid warehouses |
ELT into flexible warehouses and lakehouses |
|
Tool integration |
Tight vendor lock-in |
Modular, best-of-breed components |
|
User access |
IT-controlled dashboards |
Self-service analytics with governance |
|
Scalability |
Vertical scaling limits |
Horizontal, unlimited growth |
Why the modern data stack matters now
The modern data stack is the foundation of AI-ready data infrastructure. Without it, your AI agents don’t have the clean, accessible, scalable data they need to deliver value. Fortunately, what tech giants used to build with hundreds of engineers is now accessible through cloud-native tools like Snowflake, dbt, and ThoughtSpot Analytics.
Who it serves
A modern data stack democratizes data analytics to provide value across your whole organization:
Business users who need self-service access to insights without technical barriers
Analysts who require powerful tools for complex data exploration and modeling
Developers who build data products and integrate analytics into applications
Start Getting Better Insights
Benefits of a modern data stack
Greater efficiency
Modern systems are designed with better standards for usability and manageability. Managing a Massively Parallel Processing (MPP) database used to require a full team; now, cloud data warehouses can be managed with a fraction of your team's bandwidth. Tasks that once demanded specialized database administrators, such as capacity planning, performance tuning, and backup management, are now automated or simplified through intuitive AI-powered interfaces.
This efficiency extends beyond infrastructure. Self-service analytics reduces the burden on data teams by empowering business users to answer their own questions through AI search and natural language queries. This frees analysts to focus on high-value work like improving data models, building new capabilities, and training machine learning models that deliver even deeper insights.
Innovation through agility
Innovation velocity depends on how quickly you can move from idea to validation. If validating or invalidating a hypothesis is too costly, many teams won’t even start. Having the ability to quickly access data for hypothesis testing can be a true sink-or-swim difference.
The modern data stack accelerates experimentation dramatically. Teams can spin up new data sources, test hypotheses, and iterate on insights in days or hours instead of waiting weeks or months. This speed is critical for AI and machine learning, where rapid experimentation with features, models, and training datasets separates successful initiatives from stalled proof-of-concept projects.
💡Perspective: American Express Chief Data Officer (CDO) Pascale Hutz explains in one of our favorite Data Chief episodes:
"Data has to be a living, breathing organism. When you have that mindset, you don't think of data as finished. Platforms never reach a point of arrival because there's always something else coming. Today it's cloud, but five years from now it's going to be something else."
Increased velocity
As startups experience hyper-growth, complexity in the data stack hits faster than expected. Scaling data volume is relatively straightforward, since cloud infrastructure makes it easy to add storage and compute capacity. However, many mid-size companies maintain hundreds of dashboards supported by hundreds of transformation jobs without knowing which deliver value, while battling month-long backlogs of business requests.
Modern data stacks fix this with self-service analytics that let users answer their own questions. AI features like natural language search and automated insights cut the time from question to answer from weeks to seconds, with no manual dashboards required.
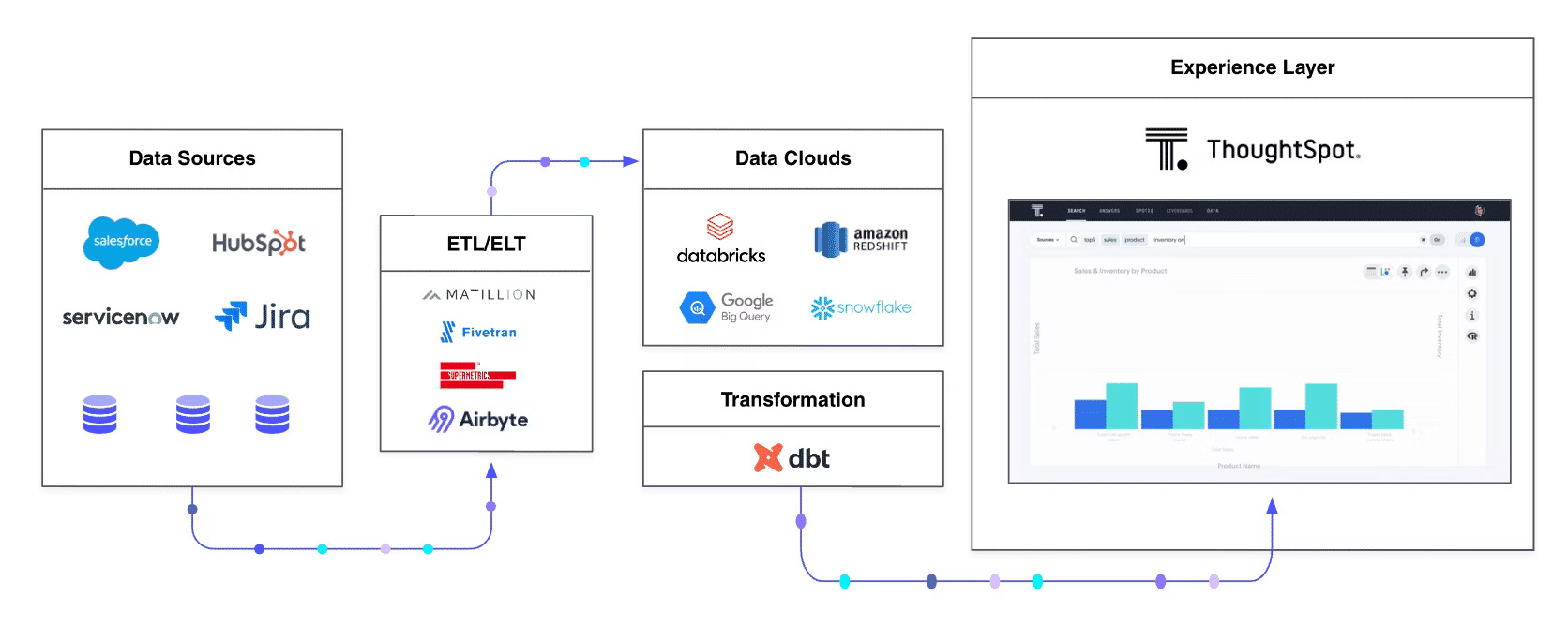
The 5+1 layers of the modern data stack
|
Layer |
Function |
Example Tools |
|
1. Data Sources |
Where raw data originates |
Salesforce, ServiceNow, HubSpot, product events |
|
2. Ingestion/EL Tools |
Extract and load data from silos |
Matillion, Airbyte, Fivetran, Supermetrics |
|
3. Cloud Data Warehouse |
Centralized storage for organized data |
Snowflake, BigQuery, Databricks, Redshift |
|
4. Transformation |
Prepare and model data for analysis |
dbt, SQL models, metrics layers |
|
5. Analytics & BI |
Visualize data and generate insights |
ThoughtSpot, Looker, Tableau |
|
6. Activation |
Push insights back into operational tools |
Reverse ETL, data apps, API integrations |
1. Data sources
This is where your data originates—think Salesforce, ServiceNow, HubSpot, and product usage events. These sources produce massive amounts of raw, unorganized data that you need to make sense of for your business.
2. Ingestion and EL tools
To provide value and avoid data silos, information must be extracted from its sources. Tools like Matillion, Airbyte, Fivetran, and Supermetrics organize your data in preparation for the cloud data warehouse.
3. Cloud data warehouse
A cloud data warehouse stores your organized data in a scalable, managed environment. Modern platforms like Snowflake, BigQuery, and Databricks separate compute from storage, allowing elastic scaling based on your demand.
4. Transformation tools
Transformation tools like dbt work inside your cloud data warehouse to clean, model, and prepare data for analytics. This layer handles the difference between extract-load-transform (ELT) and extract-transform-load (ETL) approaches.
5. Experience and analytics
This layer is where you and your business users interact with data to draw insights. Modern analytics platforms like ThoughtSpot make data accessible through natural language queries and interactive dashboards, moving beyond the static reporting limitations of traditional BI tools.
6. Activation and data products
The newest “plus-one” layer pushes insights back into operational systems through reverse ETL and data applications, completing the data lifecycle by activating insights where decisions are made.
Three principles of a modern data stack
Cloud-native and massively scalable
Modern tools are built as SaaS offerings that scale elastically with demand. They handle three dimensions of scale:
Data volume: Delightful performance with hundreds of billions or trillions of records
User concurrency: Support for tens of thousands of internal users or millions of external customers
Use case complexity: Manage growing complexity without creating technical debt
Legacy tools built around dashboards, cubes, and extracts often fail at scale because each new business question requires repetitive work, leading to thousands of unused dashboards and reports. Cloud-native platforms are built for scale from the beginning, so you can handle exponential data growth and user demand without performance degradation or architectural rewrites.
Modular and composable
Modern data stacks embrace modularity, allowing you to choose the best tool for each layer rather than being locked into a single vendor's ecosystem. This approach delivers several advantages:
Flexibility: Swap components as better solutions emerge without rebuilding your entire infrastructure
Best-of-breed selection: Choose specialized tools that excel at specific functions rather than settling for mediocre all-in-one platforms
Reduced vendor lock-in: Maintain independence and negotiating power across your technology partnerships
Faster innovation: Adopt new capabilities by integrating cutting-edge tools without waiting for your primary vendor to catch up
This mirrors the shift in network management—instead of manually configuring individual routers, everything can now be managed programmatically through a control plane. Your data infrastructure works the same way, with each component exposing APIs and standard interfaces that allow orchestration across the entire stack.
Programmable and automatable
Modern tools feature scriptable interfaces like LookML from Looker or TML from ThoughtSpot for analytics, and dbt for transformation. This code-based approach provides several benefits:
Version control: Manage changes and revert undesired modifications
Reuse: Define things once and apply them across multiple use cases
Knowledge sharing: Share workflows through code within developer communities
Automation: Scale operations beyond manual capacity
Together, these programmable capabilities transform data infrastructure from a collection of manual tasks into an automated and scalable system that grows with your business needs.
Modernizing your data stack strategy
Building a modern data stack requires a comprehensive data strategy that encompasses people, processes, governance, and AI readiness. This strategy considers how tools work together to create sustainable competitive advantages while preparing for future innovations like generative AI and automated decision-making.
How to adopt the modern data stack
I've spent years helping organizations navigate this transition, and the question I hear most often is: "Where do we start?" The answer isn't always obvious, but I've found that successful adoption follows a few consistent patterns.
1. Shift your mindset
Adopting the modern data stack requires a cultural shift in how your organization thinks about data. Cloud data warehouses like Snowflake and Google BigQuery offer architecture and pricing designed for growth, so you can store unlimited history and respond to new data requests with agility.
Self-service analytics tools like ThoughtSpot encourage analysts to focus on strategic work like improving data models while business users answer their own questions. This shift requires organizational commitment to changing how teams operate, but the payoff is substantial: faster decision-making, reduced bottlenecks, and a data culture where insights drive action instead of waiting in a queue.
2. Go best-of-breed
The industry oscillates between choosing the best solution for each layer versus choosing integrated ecosystems. During periods of rapid innovation, best-of-breed typically works better than vertical integration. Right now seems ideal for selecting the best tool for each stack layer.
While cloud infrastructure providers (AWS, GCP, Azure) offer their own tools at every layer, they prioritize customers choosing their cloud platform over winning every component battle. This creates openness and support for anyone building great customer experiences.
3. Build vertically for quick wins
Rather than building horizontally across all data before thinking about transformation or analytics, pick one vertical like Product Experience or Sales Operations. Build an entire stack for that use case and deliver value immediately.
This focused approach lets you prove ROI quickly, learn what works, and build momentum. Once you've demonstrated success, replicate the pattern across other verticals. The winning formula: deliver value fast, then scale systematically.
4. Don't let perfect block data democratization
Teams often hesitate to give business users direct data access, fearing mistakes or misinterpretation. But leading organizations solve this through governance frameworks that balance accessibility with control, including role-based permissions, certified datasets, and clear data lineage.
The other common fear: "My data isn't clean enough for self-service." Often, the counterintuitive truth is that exposing data to more users is one of the fastest ways to improve data quality. Business users quickly surface inconsistencies and errors IT teams might never discover. Waiting for perfect data means waiting forever—and missing opportunities.
ThoughtSpot's role in the modern data stack
We built ThoughtSpot to solve a problem I saw time and again in data analytics: how to make analytics at scale accessible to everyone from sales staff to executives, not just engineers. ThoughtSpot serves as the AI-powered analytics layer of your modern data stack, letting anyone ask questions in natural language and get instant answers.
Connect directly to Snowflake, BigQuery, Databricks, or any cloud data warehouse to unlock self-service analytics for thousands of users. Through powerful APIs and embedded capabilities, you can build data products and activate insights across operational systems.
See the difference for yourself. Start your free 14-day trial of ThoughtSpot—no credit card required, full platform access included.
Modern data stack FAQs
Is the modern data stack only for startups or also for enterprises?
The modern data stack benefits organizations of all sizes. While startups can build from scratch, enterprises often adopt incrementally, modernizing one vertical at a time to minimize risk while gaining immediate value.
How do I know if I should upgrade from my legacy data stack?
Consider upgrading if you're experiencing:
Long wait times for data requests
Difficulty scaling analytics to more users
Significant manual work maintaining dashboards and reports
Modern tools typically reduce these pain points dramatically. Cloud-native platforms automate manual processes, enable self-service analytics that eliminate request backlogs, and scale elastically to support growing user bases without performance degradation or infrastructure rewrites.
What's the first layer to modernize if I'm on a tight budget?
The analytics layer is often a great place to start. Tools like ThoughtSpot can connect to existing data sources and provide immediate value through self-service capabilities, reducing the burden on IT while improving business user productivity.
How does the modern data stack need to evolve for AI and generative AI use cases?
The stack is evolving to include semantic layers, vector databases, and AI-native tools. Features like automated data preparation, natural language interfaces, and intelligent recommendations are becoming standard rather than add-ons.



