


Imagine this: You're at the new French restaurant everyone's raving about. You're excited, hungry, and ready to order. But when you open the menu, you’re hit with words like confit de canard aux cerises.
Your heart sinks. The waiter hovers expectantly. You try to explain what you want, but all you get are puzzled looks.
Now, what if you could simply say, ‘I want a simple chicken dish with wine sauce, nothing too heavy,’ and the waiter gets it right away? Twenty minutes later, the perfect dish arrives.
That’s what Natural Language Processing (NLP) does for your business.
Instead of being confused by different dashboards, reports, and tools, you just ask your most capable AI system a question in natural language and gain instant answers.
Here’s how it works in real life.
Table of contents:
Natural Language Processing is a branch of artificial intelligence that focuses on enabling computers to understand, interpret, and generate human language in a way that is both meaningful and useful.
Think of it as the hidden engine powering many of the AI agents and virtual assistants you interact with daily, from search engines and chatbots to voice assistants and sentiment analysis. This means you can simply type or speak your questions, like 'Draft a quick summary of Q3 marketing report’, and the system understands exactly what you mean, delivering clear, accurate answers in seconds.
At its core, NLP transforms your questions into immediate action, helping you stay ahead of the curve.
Reducing bottlenecks
Waiting around for a simple report is bad enough. But when key projects get stuck because one person is swamped with routine requests, that’s when bottlenecks really start eating into your profit.
And the biggest culprit? All those repetitive tasks.
Natural Language Processing cuts right through that red tape. Instead of waiting for days, you can simply type your queries and take action right away. This instant access shrinks backlogs and frees up your experts for more strategic work.
💡Just look at Austin Capital Bank. By embracing ThoughtSpot’s natural language search, they cut through operational bottlenecks and grew revenue margins by almost 30%. It’s a perfect example of how everyday questions can drive real results.
Improving decision-making
Let's be honest: manually sifting through thousands of rows of data just to understand customer sentiment is next to impossible. Even with legacy BI solutions, you can't get to insights fast enough to actually move the needle.
But with NLP, your BI tools finally understand you—your questions, your intent, and what you really need. Once you type your query, the system scans huge volumes of data in seconds, discovering subtle trends across your business. With this kind of AI-powered analytics, you can make smarter decisions, right when it matters most.
🔍 Go beyond surface-level questions. See how Spotter, ThoughtSpot’s AI Analyst, helps you find hidden trends, compare performance, and dig deeper—all from one search.
Elevating digital experiences
Together, NLP and machine learning make it so much easier to create content that really clicks with your customers. Whether they’re shooting a quick query, talking to a virtual assistant, or just browsing your site, these tools help you deliver exactly what they’re looking for.
Here’s what that looks like:
Tailored blog posts and articles: NLP helps you spot trending topics, understand what your audience actually cares about, and find the right keywords, so you’re not guessing what to write next.
Hyper-personalized recommendations: Instead of pushing the same headlines to everyone, machine learning adjusts headlines, summaries, featured stories, or recommendations in real time to match each user’s interests.
Conversational content: Chatbots and virtual assistants powered by NLP can deliver responses that feel natural and human, making every interaction smooth and engaging.
Ultimately, NLP isn't just about creating content; it's about making every digital touchpoint feel incredibly personal and effective.
Research predicts the Natural Language Processing (NLP) market will soar to an impressive US$201.49 billion by 2031. This significant growth reflects NLP's increasing value in transforming data into actionable insights and meaningful understanding.
The key to this groundbreaking capability lies in a range of advanced techniques, including:
Tokenization: Breaks text into smaller units called tokens, which can be words, phrases, or symbols. Tokenization is the first step in preparing text for analysis and model training.
Named entity recognition: Detects and classifies key entities (like people, organizations, or locations) mentioned in text. This helps the system extract meaningful, structured information.
Sentiment analysis: Determines the emotional tone or sentiment behind a piece of text, providing insights into opinions, attitudes, or feelings expressed.
Lemmatization: Converts words to their base or root form, improving consistency in data.
Parsing: Analyzes the grammatical structure of sentences to identify relationships between words and phrases.
Text summarization: Condenses a text document to its essential points while retaining key information.
Topic modeling: Identifies key topics within a collection of documents and discovers main themes and patterns.
Part-of-speech tagging: Assigns parts of speech (noun, verb, adjective) to each token in a sentence to understand the structure and meaning of sentences.
Data analysis
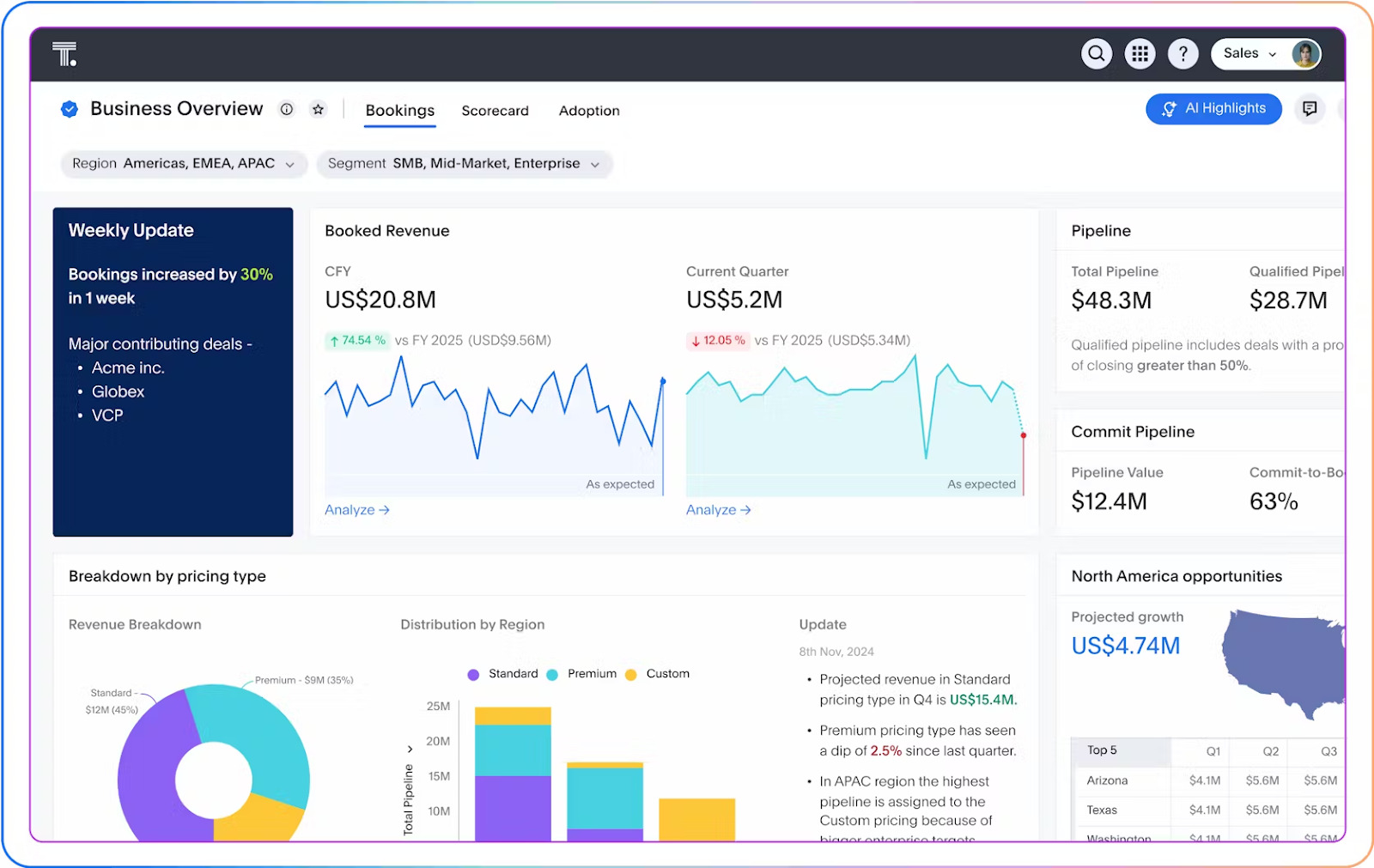
Say your sales team is closing fewer deals this month. In the past, this might have meant hours spent meticulously pulling data from ten different spreadsheets, cross-referencing figures, and manually searching for answers.
Now, with conversational analytics, you just open your AI-powered BI tool and ask a simple question, the same way you’d ask a colleague: “Show me last quarter’s sales numbers.”
Immediately, the system presents you with trend analysis showing that most of the dropped deals are coming from one specific region.
With that precise, context-aware insight, you can quickly adjust your strategy, roll out targeted incentives for that region, and course-correct before the dip significantly impacts your overall numbers.
Now, you're not just reacting—you’re making moves backed by real evidence.
Chatbots and virtual assistants
Consider your daily grind: those overflowing inboxes, calendar juggles, and endless reminders. All that administrative stuff really eats into the time you could be spending on your actual job, right?
Luckily, AI agents and assistants, powered by Natural Language Processing (NLP) are here to simplify it all. You just tell them what you need, whether it's scheduling, organizing, or reminding, and they handle the heavy lifting automatically.
The payoff? A hassle-free experience. You're freed from the daily administrative drag, finally able to pour your energy into the more important, fulfilling aspects of your work.
Content recommendation engines
Customers interact with your retail brand in countless ways, far beyond just clicking "buy." Think about it: they leave product reviews, write customer service inquiries, engage on social media, or describe items using search engines. All of this generates a wealth of 'unstructured data'.
Natural language processing analyzes all that text to truly understand not just what your customers are saying, but how they truly feel about your products and their overall shopping experience. For example, if a review mentions a "flattering fit" or "eco-friendly materials," NLP captures those nuances.
Armed with these valuable insights, you can then strategically power:
Smart product recommendations.
Highly tailored emails.
Personalized offers.
So, every communication you send feels less like generic spam and more like a helpful suggestion.
Text summarization
Ever had to skim through a massive report right before a big meeting? Instead of reading every single word, imagine using a summarization tool that instantly pulls out the key points for you. Suddenly, you’re ready to talk through the important stuff, no last-minute panic.
NLP is the power behind these handy tools. It works by extracting key sentences and phrases or generating concise summaries, helping you focus on what matters most.
Translation tools
You're collaborating with someone incredible from another country, but you don't speak their language. Awkward, right? Luckily, real-time translation tools let you chat or email back and forth without missing a single beat.
The magic behind this? Natural language processing. It helps these tools to translate accurately by considering the language's structure, conversation context, and even those tricky cultural nuances. That way, your message comes through clearly every time.
Semantic understanding
Deep semantic understanding remains a challenge in NLP.
Sure, AI models are great at picking up how words relate to each other and analyzing big data, but really grasping the deeper ideas and context behind them? That’s much harder.
Think about it: humans use nuance, tone, culture, and sometimes even sarcasm or hidden meanings. For even the most advanced LLMs, that’s a lot to decode. So when a task needs complex reasoning or really deep, specialized knowledge, your NLP models can get it wrong.
⛏️ Fix: Utilize knowledge graphs to give AI models real-world information. This improves their understanding of concepts beyond surface-level data.
Biases and hallucinations
Here’s a big one: AI models can sometimes be biased, which means they might unintentionally make unfair decisions.
For example, a hiring tool could accidentally favor certain backgrounds just because the data it learned from was skewed. If some groups were underrepresented in the training data, the model reflects it, leading to products or services that aren't fair or effective for everyone.
While these biases are often unintentional, they highlight one of the dangers of AI—the potential for reinforcement of societal biases or the creation of inaccurate outcomes that could harm decision-making processes.
⛏️ Fix: Use diverse and balanced datasets, regularly monitor performance algorithms, and set human-in-the-loop feedback mechanisms for proper oversight.
Privacy and ethical concerns
The widespread use of NLP has raised privacy and ethical concerns. These include:
Authenticity: Since NLP generates human-like text, it raises questions about the authenticity of content. Wrong or biased responses could lead to misinformation, manipulation, or even fraudulent activities.
Privacy: Most NLP models are often trained on vast amounts of data, some of which may contain sensitive or personally identifiable information. This puts user privacy at significant risk.
Intellectual property: NLP can create content that closely resembles copyrighted material, leading to potential legal disputes and questions about the ownership of AI-generated content.
Empower everyone to work with trusted, connected insights
The future of LLMs and NLP holds immense potential. However, as these powerful models get smarter and more autonomous, they also introduce new complexities and risks for your business.
That’s why you don’t just need another AI tool—you need an AI partner you can trust.
ThoughtSpot is that partner. Unlike other AI solutions, ThoughtSpot leverages advanced semantic models and a unique human-in-the-loop feedback system. That means it learns your business language, understands your context, and delivers trusted insights right where your teams already work.
Bridge the gap between people, data, and AI. Sign up for a ThoughtSpot demo today!



