


Data modeling is the process of organizing your data into a structure, to make it more accessible and useful. Essentially, you’re deciding how the data will move in and out of your database, and mapping the data so that it remains clean and consistent.
ThoughtSpot can take advantage of many kinds of data models, as well as modeling languages including its own ThoughtSpot Modeling Language (TML) which will automatically generate scriptable models. Since you know your data best, it’s usually a good idea to spend some time customizing the modeling settings. This will make the data more intuitive to search for your end users.
There are 3 common types of data models: relational, hierarchical, and network database. In this article, we’ll break down each one and explore the pros and cons, so you’ll know when you should use each type to model your data.
Relational data model
A relational data model groups data into tables called “relations” which are organized in rows and columns. Every row or “tuple” contains a series of related data values, and the table name and column names or “attributes” tell us what those values are.
Example of a relational data model
Here’s an example of a basic relational data model:

Here, the relation (table) is student accommodation. The attributes are the columns that define the data – STUD_NO, SURNAME, etc.
As you can see, the information in the HOUSE_CODE column only makes sense if you also have the information about what each code means. This would be stored in another table:

The kind of data included in the column is called the domain. Think of this as the Column Type you’d see in a database—what kind of information the column contains.
For instance, the AGE column can contain any possible age. The PHONE column contains phone numbers. This is different from the data type—both the AGE and PHONE columns contain numbers (which is a data type) but the data in those columns belong to two different domains.
Components of relational data models
Relational data models have three components:
Data structure: The set of relations and the set of domains that define how the data can be represented;
Data manipulation: How you can work with the data in the model to make it easier to read or more structured;
Data integrity: The rules that define how the data is protected and ensure that stored data is valid.
Start Getting Better Insights
When should you use a relational data model?
If your data is easily structured into categories, and you can define the relationships between data points, you’re probably best off using a relational data model.
For example, if you want to model data about student exam results, then a relational model would make sense because the data would be standardized, easy to organize, and consistent over time.
You’d organize it like this:
Relation: June 2022 exam results
Columns: Exam name
Rows: Student name
Data points: Grade received
Relational models are also well-suited for handling slowly changing dimensions (SCDs), such as business attributes that evolve over time, like a student’s address or a course instructor. These models provide the structure needed to track changes accurately without losing historical context.
If your data lacks structure, definition, or organization, then it can be tricky to use a relational model, although certainly not impossible.
Advantages of using a relational database
Relational databases remain one of the most popular approaches to data modeling, and with good reason:
Increased scalability and efficiency: A relational database can be easily scaled up or down as needed. For example, if you need to add more data to a table, you can add a new column. Relational databases are also more efficient than other types of databases because they only store data relevant to the current task.
More reliability and integrity: A relational database enforces rules that ensure data integrity, security, consistency and accuracy. For instance you can set up rules like:
-
Every customer must have a unique ID to ensure that there are no duplicate IDs and that each customer can be uniquely identified.
-
All customer names must be entered in uppercase to keep the names consistent and easy to read.
-
Only authorized users can access customer data, ensuring sensitive data is kept secure.
Disadvantages of using a relational database
Inflexible: Relational databases can be inflexible, particularly when it comes to changes. For example, adding a new column to the table may require you to modify multiple other tables and write complex SQL queries in order to do so. This takes considerable time and may require expert knowledge.
Sometimes slow: When dealing with large amounts of data, relational databases’ processing can slow down. This is because they need to process multiple SQL queries to retrieve the desired information.
Complex: Relational databases can involve complex data relations. For example, if you want to relate two pieces of data, you may need to use multiple table joins and write complicated SQL queries.
💡Relevant read: Query optimization in SQL
Hierarchical data model
A hierarchical data model is a way to organize data into a hierarchy that looks a bit like a family tree. There is a parent record, called a “root node,” with multiple “child nodes” connecting to it through links. There is only one parent node for each child node (although the parent node can have multiple children).
Example of a hierarchical data model
A good example of a hierarchical data model would be a directory. For example:
In this example, the root node is Electronics, which has two subcategories, or “child nodes”—Televisions and Portable Electronics. These categories or also a parent category to their own child nodes—for instance, under Television we see Tube, LCD, and Plasma. However, all the directories (records) fall under one single parent, the root node.
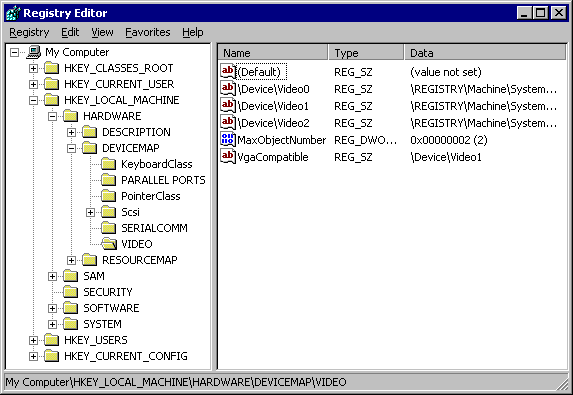
It’s most appropriate to use a hierarchical data model for data that’s already arranged in a parent-child pattern, with a single root point spanning out into multiple branches. For example, think of an org chart with multiple individual employees reporting to a single manager. Most of us have seen an example of a hierarchical data model in action—the Windows Registry in the Microsoft Windows operating system is a hierarchical database.
Advantages of a hierarchical model
The hierarchical data model has been popular since its inception, and it’s simple to see why:
Easy to understand and use: The hierarchical data model mirrors the way we organize information in our minds. This makes it a natural fit for many applications, such as databases, file systems, and document management systems.
Offers improved performance: When data is stored in a hierarchical structure, users can access related information with a single operation, which is much more efficient than retrieving data from separate tables.
Easy to maintain: Maintaining this type of model is simple because all of the data is stored in a single table, so you don’t need to keep track of multiple tables to keep the data consistent across the entire system.
Simplifies complex information: The hierarchical data model breaks down complex information into smaller, more manageable pieces. This makes it easier to work with large amounts of data.
Supports multiple views of data: This model supports multiple views of data, which is important for applications that need to provide different users with alternate views of the same information. For example, a database system could allow managers to see employee data in a hierarchical structure, while employees could see the same data in a flat structure. This flexibility is not possible with other data models.
Disadvantages of a hierarchical model
Limited flexibility: A hierarchical data model is fairly rigid, since the data is organized in a strict tree structure. If you want to add or remove data, you may need to rework the entire structure. This can also make it hard to query, since you need to follow the path through the hierarchy to find the desired information.
Data redundancy: In a hierarchical data model, child nodes often contain duplicate copies of the data stored in their parent nodes. This can lead to wasted storage space and inconsistency in the data.
Network data model
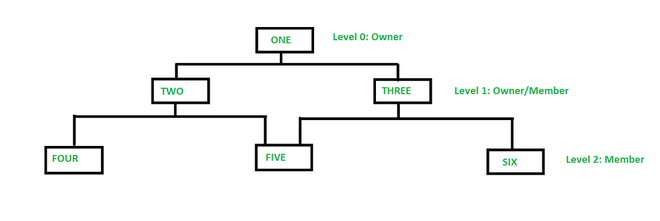
A network data model is an organization of data in a more flexible series of relationships. It’s like a hierarchical data model, but child nodes can have multiple parent nodes instead of just one.
The terminology used is different too. Instead of parents or root nodes, network data models have owners. The data points that form the next level down in the hierarchy are called members.
Network data models are a natural progression from hierarchical data models. They allow for more flexibility and complexity in the relationships between data points.
Example of a network data model
Advantages of a network model
The network model is essentially an evolution of the hierarchical model and offers some significant advantages:
Can represent simple and complex relationships: Unlike hierarchical models, network models can express both simple and complex relationships between data points. They can capture data with a one-to-many structure (the org chart with one boss and multiple direct reports) and many-to-many (say, a matrix org chart where each employee can have multiple bosses).
Simplified database design and implementation: Like hierarchical models, network data models are simple and logical to design and implement.
More efficient way to query, update and delete data: Any modifications made to the parent data automatically are reflected in the child data, making it quicker to make changes to batches of data. (However, it’s worth bearing in mind that making structural changes to the model is complex. All the data are so interconnected that if you want to modify a set of data, you’ll also have to track down and change all the data that connects to it too.)
Improved data retrieval performance: Thismodel has multiple pathways through the relationship between the data points, making it easier to access data.
Easy to use and understand: Network data models allow designers to quickly and simply capture relationships between data points in an intuitive, logical manner.
Disadvantages of a network model
Limited scalability: A network data model has less scalability than other models because the relationships between data elements can become more complex as the database grows.
Difficult to query: Querying a network data model can be challenging in this model because the relationships between data elements are more complex and difficult to understand.
Lack of flexibility: A network data model is not as flexible as other models, such as the relational model. This means that it is harder to make changes to the data structure without affecting the overall structure of the database.
💡 Want to learn more about different data models? Conceptual vs Logical vs Physical Data Models: What’s the Difference?
Data modeling doesn’t have to be (too) complex.
Not all data models are created equal. You should use the right data model and tools for your specific business needs. We’ve looked at three data models: relational, hierarchical, and network. Each has its own benefits and drawbacks that you should consider when deciding which to use.
If you want to explore how to automatically generate scriptable models with TML in ThoughtSpot, you can sign up for a free trial today.



