


In 1987, economist Robert Solow declared, “You can see the computer age everywhere but in the productivity statistics.” He noted that despite massive investments in computer hardware and software, companies saw a decrease in fundamental productivity measures. Nevertheless, companies of that period continued to invest in innovation and information technology as they understood the value of the “computer age” or the “internet age.” In much the same way, today’s companies continue to invest in data strategies because they know the importance of data in the “decade of data.”
Forward-thinking leaders have long understood the value of data, whether it be better customer retention, customer acquisition, employee productivity, process improvements, or predictive analytics. However, it wasn’t until recently that they could truly realize the business value of data. With its volume, velocity, and variety, big data gave companies a glimpse of the possible; real-time IOT data ushered in a new wave of innovations; elastic computing and virtually unlimited storage gave rise to cloud data platforms like Snowflake, BigQuery, and Redshift.
New cloud-based Software-as-a-Service (SaaS) products, like those listed above, have given rise to a modern data stack. The modern data stack is an approach to data analytics that includes a composable set of best-in-breed SaaS applications, all built around data storage in the data platform. In this modern data stack, these new capabilities have significantly improved the ability of companies and data teams to deliver on the promise of data.
How it began: ETL becomes Extract Load Transform (ELT)
Prior to the wide availability of cloud data platforms, data ingestion and transformation generally followed an Extract, Transform, and Load pattern, often called “ETL.” Under this pattern, data was transformed into a data warehouse structure before being loaded into the data platform. However, cheaper, more performant cloud platforms like Snowflake, Databricks, Amazon Redshift, and Google BigQuery made it more economical to move to an Extract, Load, and Transform (ELT) approach.
ELT differs from ETL in two significant ways:
“Pushing down” data transformation to the cloud data platform (CDP) leveraging the CDP's elastic compute, performance, storage, and scale.
Processing “entire sets” of data using SQL versus “row-by-row” operations.
This new ELT approach has the added benefit of empowering the next generation of data analysts. Data transformations were freed from proprietary tools that reside outside the data platform, or developed using unfamiliar languages. Transformation logic can now be done by a greater number of analysts, working within the data platform using the lingua franca of data analytics – SQL. Out of this opportunity, many data analysts and engineers began approaching data analytics in a new, more collaborative, more transparent way; giving rise to the analytics engineering perspective.
The analytics engineering perspective
The analytics engineering perspective is a paradigm shift for many data teams and business users. This perspective borrows from many of the principles that have guided software development best practices, and applies them to the data analytics workflow. It creates a new way of working that brings data engineers, data analysts, and business users into greater collaboration.
These principles capture the essence of the analytics engineering perspective:
Data teams should leverage software engineering best practices, including version control, testing, and continuous integration/continuous deployment to build data pipelines.
Rather than just build dashboards and reports, the role of the data team is to build a data model, robust documentation, and data products that support self-serve analytics for data consumers.
Data analysts, who often have the most business context around a company’s data assets, should be empowered to participate in the data modeling process.
The analytics engineering perspective has carved out a place for itself at the intersection of software engineering, data engineering, data analysis, and even data science. This new perspective focuses on delivering analytics-ready data to analysts and business users by utilizing software engineering best practices, methodologies, and automation.
The dbt framework
Enter the dbt framework, designed to be an open set of tools and processes to make the analytics engineering approach possible.
Put simply, dbt does the T in ELT – it doesn’t extract or load data, but it’s a way to transform data that’s already loaded into your data platform. dbt enables users to transform data in the data platform by simply writing SQL select statements. dbt handles turning these select statements into tables and views in your data warehouse, and also allows for the creation of persistent references between these tables and views; thereby creating an automated dependency graph. An automated dependency graph enables users to build data pipelines using simple declarative SQL statements while abstracting the complexity of building and managing data pipelines.
dbt is a flexible framework that supports various data modeling approaches, including dimension data modeling, enterprise data warehousing, or newer frameworks like data vault.
dbt provides a framework for analytics development and collaboration by:
Leveraging version control and DevOps practices from software development.
Enabling code to be modular, improving the maintainability of the software.
Embracing quality control, testing, and proactive notifications allows data teams to identify pipeline problems before end users do.
Automating deployment across multiple environments for development, testing, and production.
Allowing for documentation development simultaneous to code creation.
Providing an open-source framework for data transformation that prevents vendor lock-in.
This framework allows data teams to work directly within the cloud data platform to produce trusted datasets for analytics, reporting, ML modeling, and operational workflows.
dbt and the analytics engineering perspective have seen massive adoption over the past few years. As a result, companies of all sizes have found that their data teams can work faster, more collaboratively, and more confidently. In turn, they are creating data-driven organizations with greater trust in data.
Why search-driven self-service analytics
Two billion humans use search every day to get instant access to massive amounts of information—no training or technical expertise is needed. This ease of use at scale inspired ThoughtSpot founders to create a new paradigm for analytics, search and AI-driven analytics, to make it easy for business users to surface their own insights in seconds. ThoughtSpot’s next-generation analytics platform combines NLP, the precision of a relational search engine with the intelligence of a robust analytics and visualization engine, and the scale of an in-memory calculation engine.
There are a few different types of search so let’s review. The first kind of search is simply traditional web search, such as Google, Yahoo, or Amazon. This form of search, also called Object Search, enables users to search across data and return a list of indexed results. This is the most common form of search found in analytics tools today. Object search makes finding existing dashboards and charts easier, but it does little to alleviate the burden on BI and data teams to continually produce new reports.
A second form of search is natural language processing (NLP) which uses complex algorithms to interpret the intent of a user’s search queries and return a probabilistic result. Unlike object search, with NLP, end users can actually begin to use search to build their own reports.
A third form is relational search which underlies a new breed of search-driven analytics solutions. A relational search engine allows anyone in an organization to search and build 100 percent accurate charts and Liveboards from their relational data—on-the-fly, in a matter of seconds.
Unlike object search, relational search engines don’t require pre-built dashboards or reports. The engine receives the natural language query and then calculates the answers and results in real-time as you type. With the combination of natural language and relational search, one can interpret your search query by mapping your terms to the underlying data to deliver an accurate answer. The result is an easy-to-use solution that enables non-technical business people to truly perform their own self-service analyses.
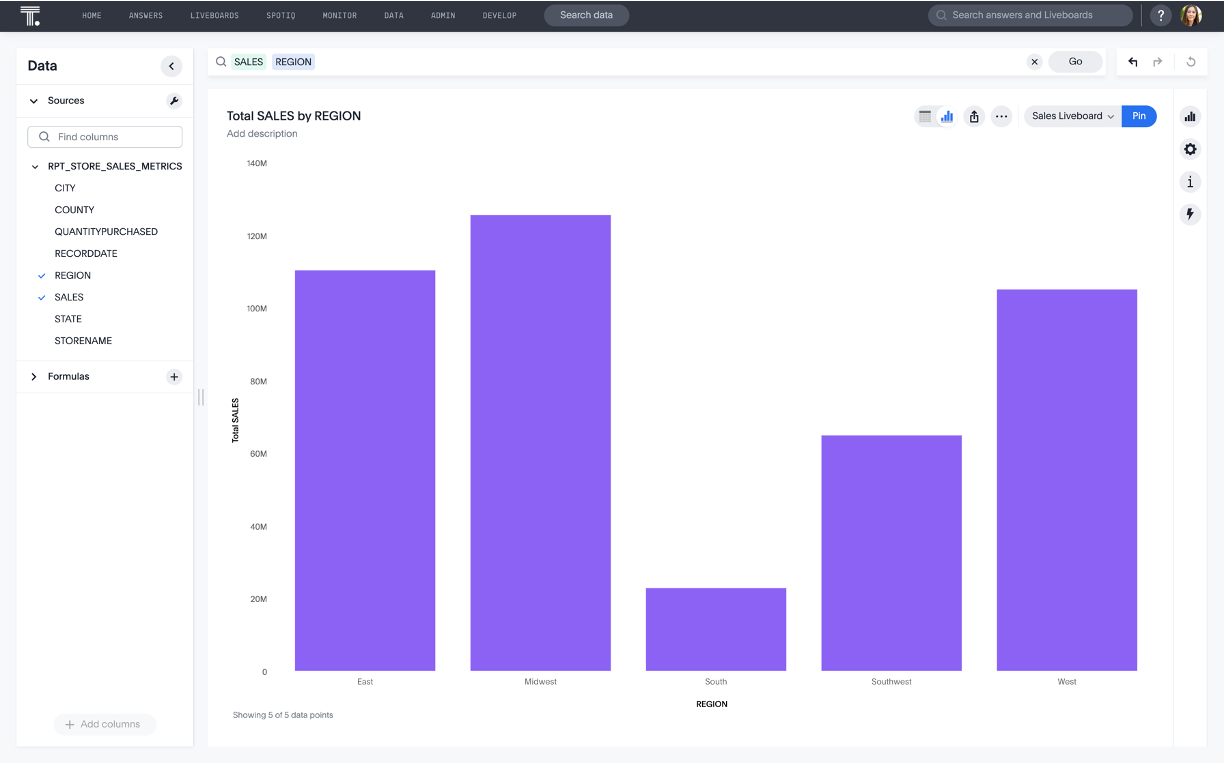
Best practices for data modeling with dbt for ThoughtSpot
ThoughtSpot bridges the gap between the analytics engineer and the business user through worksheets, which abstract and encapsulate the complexity of the underlying data model and optimize your data model for search analytics. It’s important to remember that data models should:
Be developed in collaboration with business users for a specific business process, making it easy, fast, and simple to search.
Have excellent query performance.
Be flexible and adapt to business needs.
Let’s look at a couple best practices that will help your models deliver on the principles above.
Set up your data model to get the most out of your modern data stack.
Use dbt to model and transform your data into star schemas using dimensional modeling best practices. This includes building granular facts used to calculate measures, and dimensions used to describe and categorize the measures. As stated earlier, your facts and dimensions must be aligned with the business process. The fact tables should be as granular as possible with non-aggregated data; thereby enabling business users to have the most flexibility when asking questions of data using ThoughtSpot’s search.
Ensure your primary key and foreign key relationships are properly defined in between facts and dimensions. The proper definition of joins ensures measures are calculated correctly, reduces data duplication, enables drill-down, and search, and improves performance. ThoughtSpot can import join relationships that are defined in the underlying cloud data platform or enable joins to be defined within a ThoughtSpot worksheet.
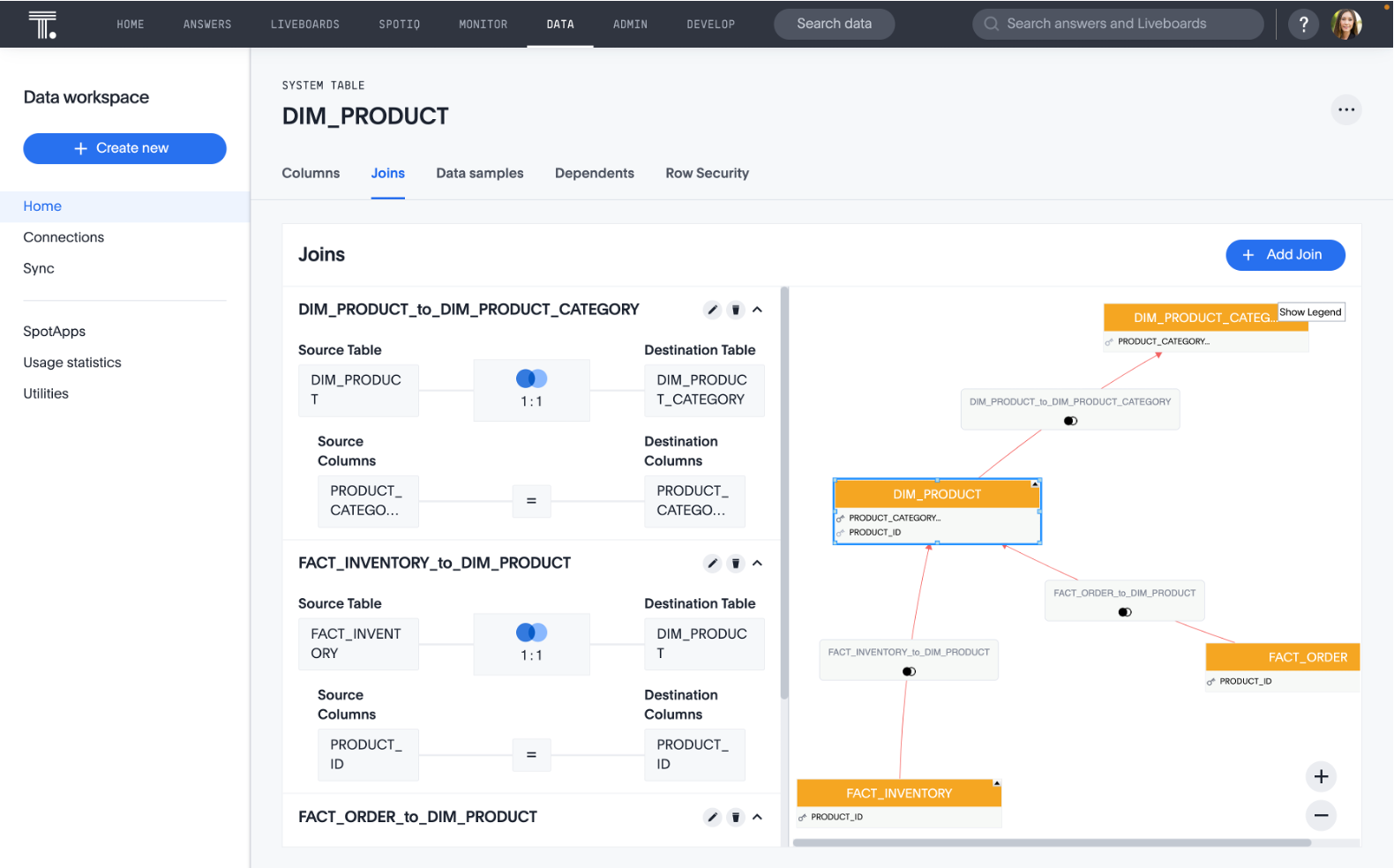
Define metrics and exposures in dbt
Exposures and metrics are the connection between your dimensional data model developed using dbt, and your insights delivered with search and AI-driven analytics in ThoughtSpot.
Both metrics and exposures are types of nodes that a user can define in dbt. An exposure can be any table or view in your dbt project. A metric is a time series aggregation over a table that can have multiple dimensions, time grains, and filters.
Defining a dbt node as an exposure or a metric allows an analytics engineer to define and describe a downstream use of a dbt view or model, such as a ThoughtSpot worksheet or Liveboard, within dbt itself. This enables the entire data team to understand exactly what parts of the upstream data model a particular ThoughtSpot object is dependent upon.
For example, this allows an analyst to easily see if a data pipeline problem will impact a particular calculation in a Liveboard. It also allows an analytics engineer to diagnose and re-run the necessary parts of the pipeline to recreate a particular Liveboard or calculation, without having to rerun an entire data pipeline. Finally, it allows the analytics engineer to see how changes to a data model will impact the data their business users see downstream.
In particular, defining metrics in dbt ensures consistent definition and reporting of key business metrics across platforms. Ensuring, for example, that metrics are defined centrally by the data team instead of ad hoc reporting by different individuals, and the same metric a user sees in one Liveboard is consistent with any other Liveboard in ThoughtSpot, and that all teams and business units across a company are working from one source of truth.
Use metadata to jump-start your data model
Transformed data reaches its full value potential when it is actively used to inform and accelerate business decisions. ThoughtSpot seamlessly integrates with dbt to bring the knowledge and business value captured in dbt models and metrics to business users via search.
The ThoughtSpot dbt integration utilizes the metadata captured in dbt to automatically translate dbt models and their defined relationships into use case specific worksheets, built with ThoughtSpot Modeling Language (TML). ThoughtSpot imports metrics defined in dbt models and instantly translates them into an interactive Liveboard. For each defined metric, ThoughtSpot creates Liveboard where data teams can easily collaborate, drill into the granular details, and use AI-technology to uncover hidden insights and trends in their data.
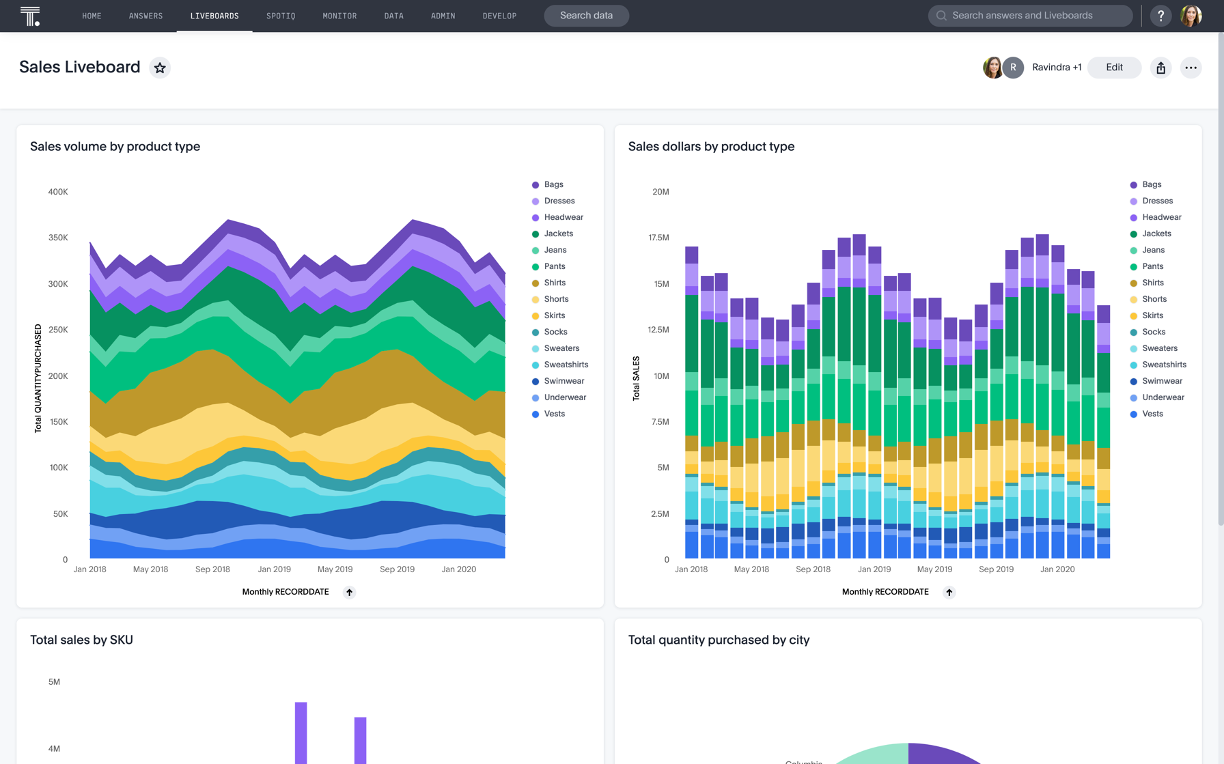
Test and document your models
The dbt framework supports testing of your models, which is consistent with software engineering best practices. Writing tests that verify and validate your data models reduces errors, and enables the data team to be confident that the data is correct, measures are correct, and the data is fresh.
The framework also enables documentation of your models, metrics, and exposures that are kept right alongside your code. Describing your models in code makes it simple to document, easy to generate detailed documentation, and provides lineage between upstream data and downstream consumption.
Common use cases
With ThoughtSpot and dbt, companies are eliminating ad hoc analytics requests from executives and marketers about marketing promotions. Executives can now answer their own questions about promotions in two minutes rather than waiting for two weeks, significantly reducing the backlog, reducing expenses, and improving time to value.
The services and operations teams make data-driven decisions based in real-time rather than waiting weeks for BI reports. Marketers and executives actively analyze campaign statistics such as conversion rates, account lifetime value, and overall ROI alongside customer details such as product mix. With the ability to easily ask the “next questions” customers have increased collaboration between the business user, analysts, and data engineering teams.
As you can see, ThoughtSpot’s search-driven analytics and the dbt framework dove-tail nicely together, contributing to the analytics engineering perspective for data operations. Leveraging ThoughtSpot as the User Experience (UX) and dbt as the data transformation layer:
Promotes true self-service and a collaborative workflow.
Increases the ability of business stakeholders to quickly gain insights from their data.
Greatly decreases the time to value from raw data to valuable insights and creates more trust in data throughout the organization.
Getting started with dbt and ThoughtSpot
Of course, you will need dbt and ThoughtSpot but also a Cloud Data Platform (CDP) to store data and manage the data transformations. A great way to get started quickly is to use ThoughtSpot’s quick start guide, “Build the Modern Data Stack with Snowflake, dbt, and ThoughtSpot”.
This quick start guide will walk through the key components of setting up your own modern data stack with free trials for Snowflake, dbt Cloud, and ThoughtSpot.



