


In The fundamentals of data warehouse architecture, we covered the standard layers and shared components of a well-formed data warehouse architecture. In this second part, we’ll cover the core components of the multi-tiered architectures for your data warehouse.
Layers of Data Architecture
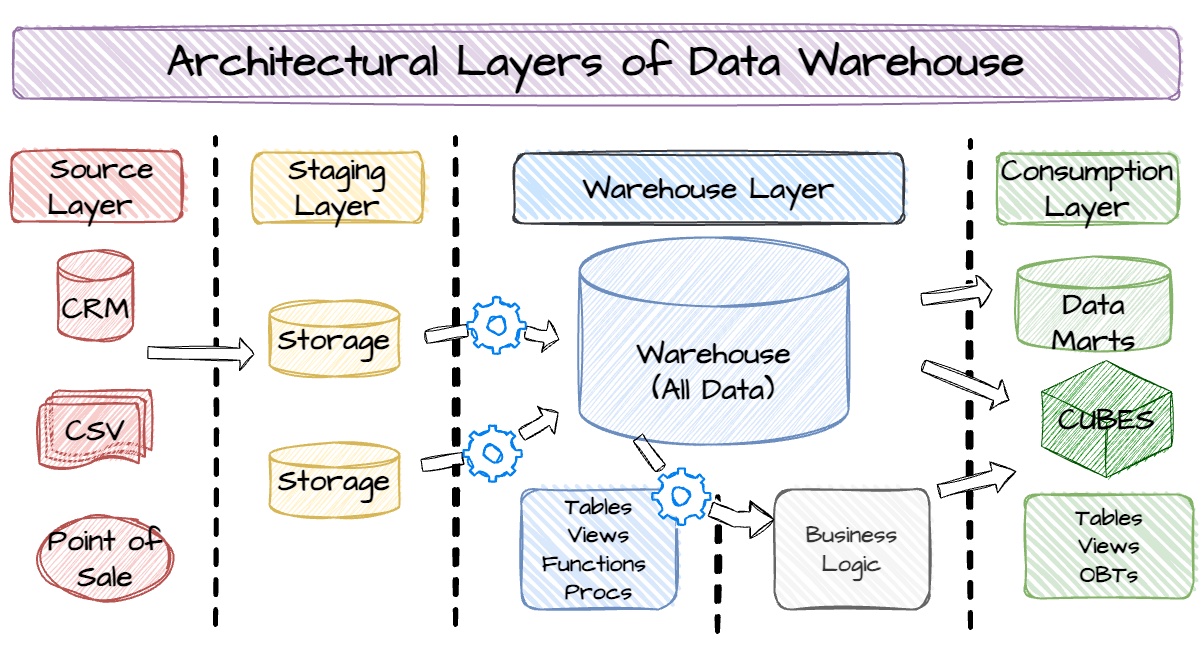
Take a moment to review the layers in Figure. You’ll notice the new Business Logic component in the warehouse layer. This component or sub-layer represents the processes and structures that implement business rules. It serves as a centralized location for all business rules to ensure consistency. The business logic layer is typically not accessible to end-users. Instead, it’s accessible through the consumption layer. How this layer is constructed or accessed depends on the chosen warehousing methodology.
Warehousing methodology
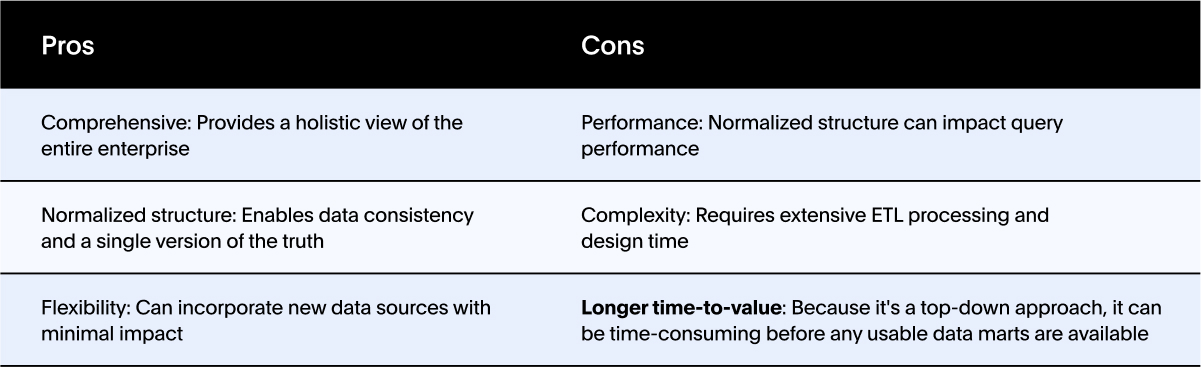
There are several popular warehouse methodologies to choose from. Each of these data warehousing methodologies—Data Vault, Corporate Information Factory (CIF), and Kimball—have their unique approach and set of best practices. Selecting the correct method depends on your goals and your organization's requirements. Here’s a summary of the pros, cons, and considerations for each:
Data Vault 2.0
Data Vault may be best suited for environments with frequent changes in source systems. It is ideal for scenarios where historical tracking is critical.

Corporate Information Factory (CIF)
Created by Bill Inmon, CIF is well-suited for large enterprises with complex, interconnected data systems. If the enterprise has the resources and time, CIF can provide a detailed and comprehensive data warehouse solution.
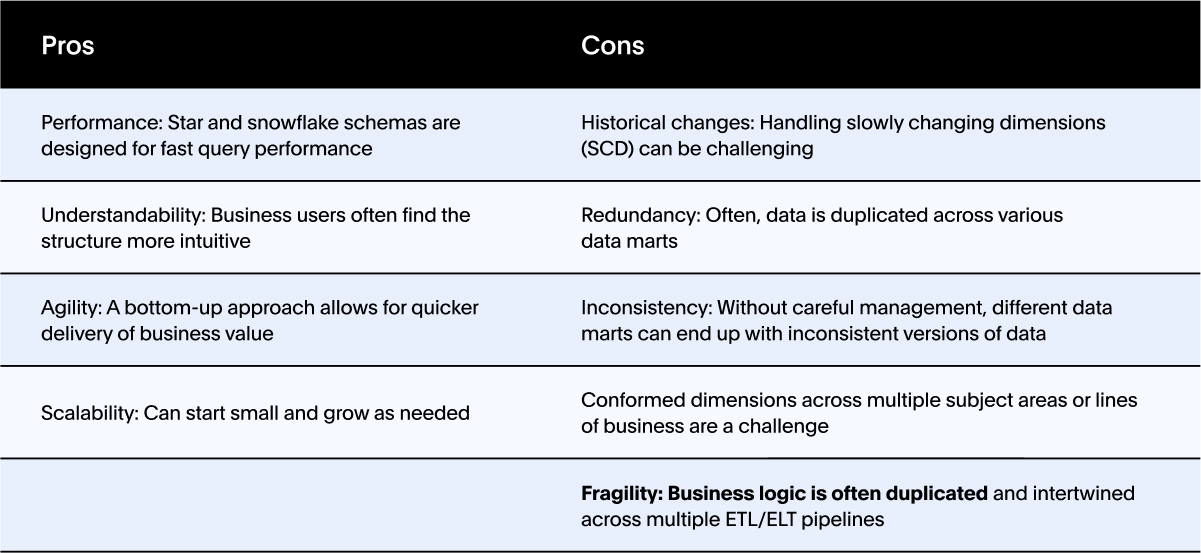
Kimball / Dimensional Modeling
Dimensional modeling is ideal for organizations looking to deliver quick wins and incremental value. Best suited for departments or teams with a specific set of analytical needs.
Start Getting Better Insights
How to select a warehousing methodology
Selecting a warehousing methodology should be a team effort, given that there is much to consider. Take the time to consider the following:
What are the primary needs of the business—speed-to-market, a comprehensive enterprise warehouse, agility, and historical tracking?
What are the technical skills needed to ensure success? Are there well-defined patterns and practices?
What are the types of data sources and the volume?
Can the approach adapt and evolve with the ever-changing business environment and modern data stack technologies?
Pro tip: In the real world, most organizations combine these methodologies, taking the best elements from each to create a hybrid solution tailored to their needs.
Benefits of a multi-tiered data warehouse
Warehouses are organized into multiple tiers to address the separation of concerns, such as security, performance, scalability, flexibility, and varying business use cases. Multi-tiered architectures in data warehouses offer a structured way to handle the complexities of modern data environments, ensuring that data is clean, reliable, easy to query, and easily accessible.
The central warehouse structure is optimized for storing all data and the relationship between entities. It is not optimized for data analytics or consumption by business users. In contrast, the consumption layer is designed for specific use cases, optimized for performance and ease of use.
Understanding the analytics consumption layer
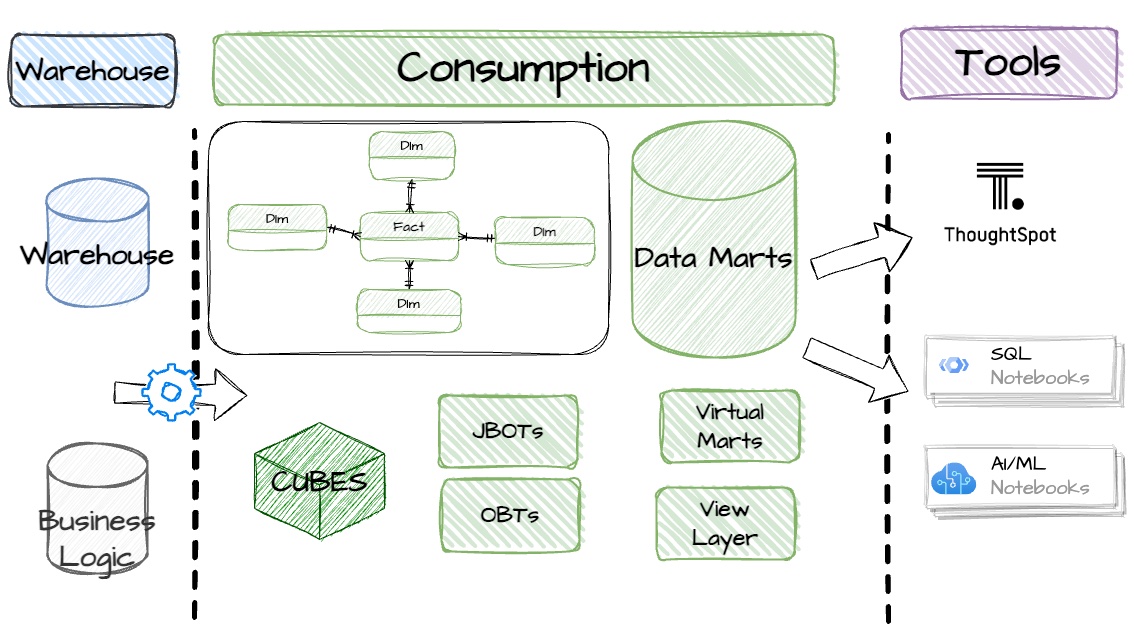
The consumption layer is where well-governed and well-modeled data in the warehouse is finally presented to business users in an understandable and useful way. This layer is the primary entry point for analysts, business users, and tools.
Access to the warehouse layer may be granted to some power users to balance the demand for increased speed to market with the need for data engineering discipline. Managing access to the various levels of the data warehouse is a critical component of a well-governed warehouse. As such, take care to ensure data is appropriately governed.
Let's delve into the key components of the consumption layer: Data Marts, Star Schemas, Cubes, and alternative structures like One-Big-Table (OBT).
Data Marts
It is essential to understand that data marts are not data warehouses; they are separate and distinct. Data Marts are subsets of data from the central data warehouse modeled for specific business applications, processes, or departments. Instead of a vast ocean of data, like in a central data warehouse, a data mart is like a pond curated for a specific group of users.
The primary purpose of a data mart is to provide data to analysts and end users in a structure that is ready for analysis, emphasizing ease of access and understandability. Often, data marts are created for specific ongoing operational analysis—like people analytics or marketing analytics.
By only pairing the data to what's relevant for a specific business operation, data marts optimize query performance and make data more accessible and understandable for end-users. Think of a data mart as a container of heterogeneous data structures. Which structures are present depends on the needs of the specific use case.
Star Schema
In a star schema, the design consists of one large central table, known as the fact table, surrounded by dimension tables. The fact table contains transactional data—quantitative data points called "measures"—and the dimension tables contain descriptive, categorical information. The structure promotes highly performant data analysis across multiple dimensions.
Managing these dimensions often involves slowly changing dimensions (SCDs), such as attributes that evolve over time, like a customer’s address. Choosing the right SCD strategy (e.g., Type 1 overwrite vs. Type 2 history) helps balance performance with historical accuracy.
Snowflake Schema
A snowflake schema builds upon the star schema by normalizing its dimensions. This organization of data within the database minimizes redundancy and heightens data integrity. Consequently, dimension tables are divided into associated tables.
💡 Relevant read: Star Schema vs Snowflake Schema: 6 Key differences
One Big Table (OBT)
OBTs are flat, wide tables or views denormalized from multiple tables (often both facts and dimensions) combined into a single, comprehensive table. These can simplify certain types of analysis or reporting. As a result, they will duplicate data, consume more storage, and present data management issues. To learn more about the pros and cons of OBTs, see data modeling best practices for data and analytics engineers.
OLAP Cubes
An OLAP cube is a multi-dimensional framework facilitating rapid data querying and analysis. It addresses the performance challenges often found in relational data warehouse models during intricate queries, particularly in business analytics. However, with the rise of contemporary cloud data warehouses and columnar databases, the necessity for OLAP cubes has significantly diminished.
View Layer
Consumption layers often feature a view layer. This view layer offers an abstraction from physical structures such as star schemas and relational joins. Designers create them to enhance reliability, flexibility, and user-friendliness. Some even use them to enforce business rules for specific departments.
Pro Tip: These are pretty useful, but be careful not to overuse them. I’ve seen views, on views, on views, which creates a more fragile and less performant consumption layer.
While a data mart can contain a variety of structures, it should not be a dumping ground for a Just a Bunch of Tables (JBOTs). A well-designed data mart answers specific business questions and processes; it’s designed to promote accessibility, ease of use, and understanding and be reusable.
Tools
The consumption layer is the access point for analysts, business users, and analytics tools like ThoughtSpot. Note the consumption layer can and should ensure that standard connection protocols are available to access data, including ODBC, JDBC, and REST.
Tools like ThoughtSpot enable self-service BI and low-code analytics for non-technical business users, while tools like Mode Analytics enable code-first analytics for data teams and analysts.
See how ThoughtSpot can help you make the most of your data architecture investment—start your 14-day free trial today.
The key to a successful data warehouse architecture: Alignment
In wrapping up our exploration of the fundamentals of data warehouse architecture, we’ve delved into the multiple layers and methodologies that underline a robust data architecture. From introducing the business logic layer to shedding light on the variety of warehousing methodologies available—it's clear that there's no one-size-fits-all approach. The path that you choose will pivot on your organization's unique goals and needs.
The essence of a multi-tiered data warehouse lies in its capacity to handle modern data environments with flexibility, assuring that the data at hand remains clean, trustworthy, and readily accessible. The journey from the depths of the central warehouse structure to the forefront of the consumption layer underscores the importance of making well-informed decisions. Whether choosing analytical tools or defining data structures, the emphasis is on data quality, trust, and streamlining data delivery for end-users.
Remember that the heart of a well-modeled and well-governed data warehouse architecture is its adaptability and accessibility, ensuring it remains aligned with an organization's ever-changing needs.



