

Why your AI agents are only as smart as the data underneath them
A CFO asks her AI agent a simple question: "What was our ARR at the end of Q3?" The agent finds the subscriptions table, spots a column called arr, sums it up, and returns $16.4M. Strong quarter. Everyone nods.
The real number was $13.9M, but no one in the room knew it yet.
I hear some version of this story from nearly every data leader I talk to right now, and it almost always starts the same way. They stand up an AI pilot. It looks sharp in the POC. Then it goes to production and starts confidently generating wrong answers at scale. So they go hunting for a better model.
But the model was never the problem. The problem is what the model knew about the business, which is to say: almost nothing. It didn't understand the fiscal calendar, the product taxonomy, or that "ARR" means three different things depending on who's asking. That's not a model gap. That's a missing layer.
I've spent years in the trenches of data modeling and analytics engineering, and this pattern keeps repeating because the foundational work that makes AI trustworthy keeps getting skipped. It's the new shape of "garbage in, garbage out," except worse. When your context layer is weak, agents don't just produce one bad report.
They replicate the same error across every query, every user, every decision, at machine speed. And a wrong answer from an agent that sounds authoritative costs you far more than a wrong answer from a dashboard that at least shows its work.
What follows is a framework for building the context layer that agentic AI actually needs: how semantic pipelines, ontologies, and knowledge graphs create knowledge to give your models the business understanding they currently lack. This is how you start without boiling the ocean.
How is a BI semantic layer different from an AI context layer?
Semantic layers are not new, and if you've been in the data space long enough, you've lived through multiple waves of this conversation.
I remember when Business Objects first introduced the concept in the 1990s: a translation layer that sat between raw database tables and business users, mapping column names to terms people actually understood.
That approach worked because the consumer was a human. A person clicking through a report and filling in the context gaps with their own judgment based on lived experiences and tribal knowledge (some may even call this wisdom, but I digress).
Agentic AI doesn't have that luxury. When an AI agent generates an answer, it has no institutional knowledge of your fiscal calendar, your product taxonomy, or the difference between gross revenue and net revenue in your specific accounting model.
Jessica Talisman (CEO and Founder of The Ontology Pipeline) and Tony Seale (Founder of The Knowledge Graph Guys) both made this point on a recent episode of Data & AI Chief podcast .
Ultimately, the shift looks like this: a traditional semantic layer defines metrics, dimensions, and joins. Tony Seal defined the AI context layer as:
Semantics: What do these terms mean to the business?
Data items: Where does the data live, and what shape is it in?
Network: How do concepts relate to each other?
Without all three, you're handing your agents a dictionary with no grammar.
What a context layer actually is
It's a stack, and each layer is necessary but not sufficient on its own. The combined stack is what turns your data into something a frontier model like Claude, Codex, or Cortex can actually reason over.
Most people think metadata and business definitions are the context layer. They're the starting point, not the destination.
Metadata tells you what physically exists: the tables, the columns, the data types, the schemas, the logs. Most modern data platforms hand this to you for free, and plenty of vendors will sell you more of it. But metadata's job is to tell you what something is called, not what it means. An agent with only metadata can find a column named arr and sum it. It cannot tell you whether that's the right ARR. That gap, between what a thing is named and what it means, is where agents fall apart.
Topology tells you how things are arranged relative to each other. Star schema or snowflake. What rolls up to what. Products belong to categories, categories roll up to divisions, subscriptions tie to accounts. This is real progress: the agent now understands structure, so it stops returning numbers from the wrong grain. But topology only describes the shape of the container. It says nothing about the substance inside it.
The real issue is this: An agent that knows the structure perfectly can still hand you a confidently wrong number, because knowing how the tables connect tells you nothing about what the business means by the words in them.
Ontology is where the meaning finally lives. Ontology captures the relationships between concepts along with their lineage, their rules, their constraints, and their sources of truth. This is the layer that knows your company has three definitions of ARR and which one applies where.
Jessica Talisman would push hard on four properties that an ontology has to have to be worth anything: sovereignty (who owns the definition and has the right to change it), machine readability (can a system consume and act on the meaning without a human in the loop), interoperability (does the meaning travel cleanly across systems and teams without degrading), and reasoning (can you derive new knowledge from the relationships you've encoded, not just look up what you put in).
Miss those four, and you don't have an ontology. You have documentation.
The Key Takeaway:
A knowledge graph is where the ontology stops being a design and becomes a thing you can query. Not a diagram on a whiteboard. Not a glossary in Confluence. A live, traversable structure where the hierarchy, the relationships, and the rules are encoded and an agent can actually walk them.
A knowledge graph is what you get when you take your ontology seriously enough to build it. An agent navigating one isn't pattern-matching against text. It's reasoning over a model of your business. And every data modeler reading this already knows the secret: a data model is a model of the business. It always has been.
Here's a stat that should give you pause: only 7% of enterprises say their data is AI-ready, according to Cloudera and HBR. The other 93% are asking agentic systems to reason over data that lacks the context those systems need to reason well.
Why do AI agents need a Knowledge Graph architecture?
Let’s come back to our CFO and her $16.4M.
Here's how the agent got there, and why each layer would have caught it sooner. With just metadata, the agent finds the subscriptions table, spots the arr column, sums it, and hands back a number. Structurally, it did nothing wrong. The answer is still wrong.
Add topology, and it gets smarter. Now the agent knows subscriptions roll up to accounts, accounts belong to segments, and there's a date dimension scoping the quarter correctly. The shape of the query is right. The answer is still wrong, because shape was never the problem.
The problem is that "ARR" means three different things inside this company. Product counts annualized MRR from every active subscription. Finance counts committed contract value only, net of discounts, excluding anything under twelve months. The board deck uses the Finance definition plus expansion from renewals signed in Q3, but not yet live.
Without an ontology that encodes which definition applies in which context, and who owns each version, the agent just picks one. Probabilistically. It picks the definition that shows up most in its training data, which is usually the broadest one, which is usually the highest one, which is usually the one that makes a CFO's eyebrows go up in the wrong direction during a board meeting.
Now add the knowledge graph, and the agent stops guessing definitions and starts reasoning over the actual deals. It knows the Meridian Corp renewal that closed in September is sitting in the ARR number at $1.8M, but Meridian's contract carries a ninety-day termination-for-convenience clause, so Finance won't recognize it as committed until December. It knows the $340K from four month-to-month accounts is real revenue but uncommitted by definition. It knows the partner-sourced deals carry a revenue share that hasn't been netted out.
Metadata alone: $16.4M. Strong quarter. Send the deck.
The full semantic stack: $13.9M committed, $1.8M deferred pending the Meridian window, $340K flagged at-risk, and a clean footnote explaining the gap before anyone has to ask.
It’s the same question, and the same database. The only thing that changed was whether the agent had enough context to reason instead of pattern-matching.
Adobe Case Study
Jessica Talisman walked through a concrete case study from Adobe that illustrates the point. Adobe needed to reconcile pre-sale and post-sale customer journeys, which lived in completely separate systems with different taxonomies.
By building an ontology that unified those taxonomies, Adobe could map the full customer arc: from first marketing touch through onboarding through learning-content engagement. The same ontology powered auto-tagging of learning content, so new resources were automatically classified and connected to the right customer segments.
Could a flat data warehouse have supported this? Technically, yes, with enough custom ETL and hardcoded joins. But every new use case would have required more plumbing. The ontology gave Adobe a reusable structure that scaled across use cases without rebuilding the pipeline each time.
What is the provenance gap, and why does it matter for AI?
This is the part I keep circling back to in conversations with data leaders, and it doesn't get nearly the attention it deserves.
When a large language model trains, provenance gets stripped. The lineage of an idea, who originated it, how it evolved, how one insight built on another, none of that survives the training process. Jessica Talisman calls this the provenance gap, and once you see it, you can't unsee it. Most data professionals, even very experienced ones, don't realize it's happening at all.
Here's the mechanics. A model's knowledge lives in its parameters, the billions of weights tuned during training. That's not a database. There's no row anywhere that says "this fact came from source X, ingested on date Y, valid under condition Z." The knowledge is baked in, and the receipt is thrown away. Which leaves the model with three blind spots:
No origin: It can't tell you where it learned something.
No currency: It doesn't know whether the fact is still true, or when it ever was.
No conditionality: It doesn't know the scope a fact applies under, so it can't tell your finance ARR from your product ARR even when the difference is the entire answer.
The parametric layer forgets, and your retrieval layer is the only place you get to put the context back.
When an agent retrieves data to answer a question, the quality of that answer is capped by the semantic richness of what it pulls. Return raw numbers with no definitions, no relationships, no lineage, and the agent is guessing. Confident guessing, at scale, is what a governance nightmare looks like.
According to Promethium's research, semantic layers reduce agentic AI data errors by 66%.
Gartner's analysis goes further: prioritizing semantics can increase agentic AI accuracy by up to 80% and reduce costs by up to 60%.
The research lines up with our intuition. 75% of data and analytics leaders admit their governance hasn't kept pace with AI adoption, per Informatica's CDO report. Trust was already the hardest problem on a data leader's desk, and it was already fragile. If your agents are answering without provenance, without source attribution, without business grounding, you're widening that gap with every single query.
Your ontology is your competitive moat
Tony Seale is blunt about this: your ontology is your intellectual property. From heavy equipment to cloud analytics, every data team I've worked with proves him out..
The relationships you define between business concepts, and the rules you encode about how products relate to customers, how revenue maps to segments, how metrics connect to outcomes, that knowledge graph is decades of institutional understanding codified into a machine-readable structure.
Jessica Talisman puts it even more sharply: "Your ontology is your digital thumbprint."
Think about what that means in practice. Every business defines its domain differently, even inside the same industry. Your customer lifecycle, your pricing model, the way your segments actually behave, all of it reflects decisions no competitor can replicate.
Which is exactly why you should think twice before handing that ontology to an external platform wholesale. If your entire business logic graph lives inside a third-party system, you've given away the one asset that differentiates your data infrastructure from everyone else's. The tactical advice here is straightforward: own the canonical version of your ontology, govern who can read and write to it, and treat it with the same IP protections you'd apply to proprietary source code.
The organizational challenge is just as real as the technical one. Building and maintaining an ontology demands cross-functional alignment between your data teams, business stakeholders, and compliance.
It surfaces the political questions of who defines what a term means, whose metric is the source of truth, and how conflicts between departments actually gets resolved. Underestimating that organizational work is a common reason context-layer projects stall.
Where to start: think big, deliver small
Tony Seale's principle here is worth adopting verbatim: think big, deliver small. And author Jim Carrol would add ‘scale fast’. So, start with one high-value use case where the lack of business context is visibly causing problems. Maybe it's a customer churn prediction that keeps misfiring because the model doesn't understand your contract structure. Or maybe it's a financial reporting agent that confuses GAAP and non-GAAP metrics because they share column names in the warehouse.
Pro Tip: Try to align this with our overall business strategy; otherwise, you’ll end up with a series of disconnected use cases.
From that use case, derive what Tony calls "competency questions": the specific questions your AI agent needs to answer correctly. Those competency questions map directly to the ontology you need to build.
Remember, you're not boiling the ocean; you're building the smallest graph that lets your agent answer the questions that matter most, then expanding from there.
A practical starting sequence looks like this:
Pick the use case where wrong AI answers cost you the most (in time, trust, or dollars)
List the 10 to 15 competency questions an agent would need to answer correctly
Map those questions to the business concepts, relationships, and data sources they require
Build a minimal ontology that covers those concepts and nothing more
Connect that ontology to your retrieval layer so the agent can access it at query time
Measure accuracy against a baseline, then iterate
I've seen too many teams try to build a comprehensive enterprise ontology upfront. Resist that temptation. A focused graph that covers one domain well is infinitely more useful than a sprawling graph that covers everything poorly.
How do you start building a context layer that works?
The pattern matters more than the vendor: governed context, explainable answers, and a semantic layer you control. That's what lets an agent's answer survive contact with a CFO who already knows the real number.
And the "you control" is the part to hold onto. You still own your moat. The ontology is yours, the canonical version lives where you govern it, and you decide who reads and writes to it. A platform's job is to reason over that ontology at query time, not to become the system of record for it. Owning the meaning and operationalizing the meaning are two different jobs, and you should never trade the first to get the second.
With that line drawn, the question becomes practical: where does the reasoning layer plug in? Look for a platform where the semantic layer isn't an afterthought bolted onto a query engine, but the platform around which the entire system is organized.
Spotter Semantics is how ThoughtSpot approaches it: the brain that holds business logic, metrics, synonyms, and governance rules so an agent understands what your data means in business terms, while the canonical definitions stay yours.
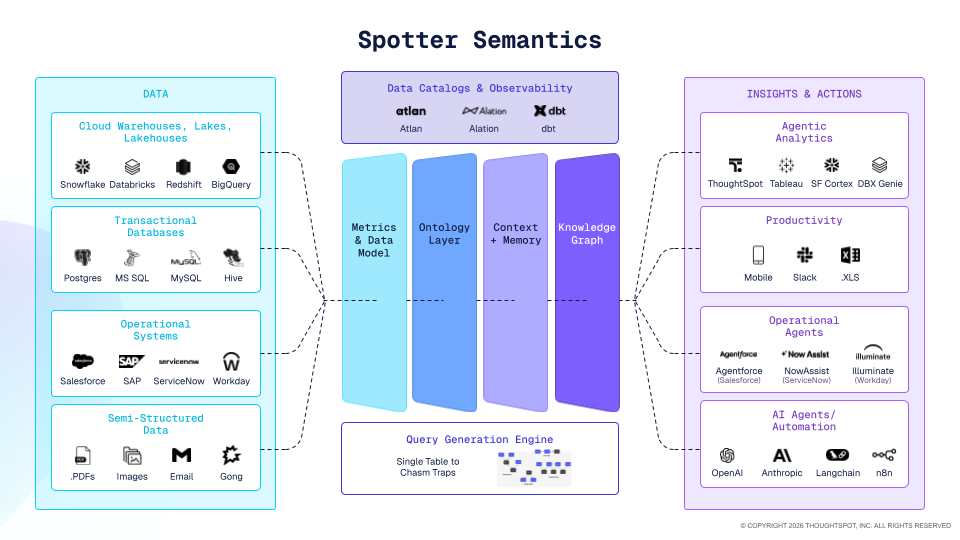
How you can get started now
Want to go deeper on the concepts in this post? Listen to the full conversation with Jessica Talisman and Tony Seale on Data and AI Chief.



