


Ever tried finding a specific book in a library where everything’s just tossed into random piles? Total nightmare, right? You’d be digging around for hours.
Now, imagine that same library with a proper cataloging system, organized by subject, author, and genre. You walk in, grab what you need, and you’re out. Easy.
This is the essence of a data warehouse. It’s a beautifully organized, single source of truth for all your business data. And the data warehouse architecture? That’s the brilliant blueprint that makes this organized library possible.
Let’s break down data warehouse architecture in a way that’s easy to understand, so instead of digging through piles of disconnected data, you’ve got answers at your fingertips.
Table of contents:
Data warehouse architecture is the blueprint for how your data is gathered from different sources, cleaned, and stored in a central repository to power business analysis and reporting.
Let’s say you run an e-commerce company. You’ve got data coming in from your website, your mobile app, your payment processor, your inventory system, and your marketing tools. Without a data warehouse architecture, all that data lives in different places and formats.
With a well-designed data warehouse architecture, you’ve got a system that pulls data from each of those sources, cleans and transforms it, and stores it in a central location. Now your ops team can track inventory in real time, and even your finance team can work from the same, trusted source of truth.
Back in the early days of data warehousing, Bill Inmon—often called the father of the data warehouse—laid the groundwork for how we think about these systems today.
In his classic book Building the Data Warehouse, he defined a data warehouse as a “subject-oriented, integrated, time-variant, and nonvolatile collection of data in support of management’s decision-making process.”
Here’s what that actually means:
Subject-oriented: Data is organized and structured around specific business topics or themes, such as sales, marketing or distribution data
Integrated: It brings together data from different sources and creates a unified system to make sure everyone speaks the same data language.
Time-variant: The warehouse stores historical data, capturing not just what’s happening today, but also noting down how things have changed over time.
Nonvolatile: Data in the warehouse is read-only; it will not be changed or overwritten, keeping historical data intact and reliable for analysis.
Modern businesses run on data. But without the right foundation, your data quickly becomes more of a burden than a benefit. It lives across dozens of tools, owned by different teams, in different formats.
And when data lives in silos, naturally, reports don’t match. Insights take too long, and ultimately, trust in the numbers erodes.
Here’s what a well-designed data warehouse architecture delivers:
1. Data-driven decisions
When every team is working with different tools, timelines, and definitions, it’s no surprise reports don’t match. Marketing has one version of the truth, finance another, and product something else entirely. The result? Confusion, second-guessing, and slow decision-making.
A strong data warehouse architecture puts an end to that. It centralizes data from across your systems and transforms it into a consistent, governed format. With standardized metrics and a shared source of truth, every team sees the same data, empowering you to make faster, more aligned decisions.
2. Faster, self-serve insights
You shouldn’t have to wait days for a simple report. But when data is scattered across tools and locked behind complex BI dashboards, even basic questions turn into long delays.
A well-architected data warehouse changes that. It centralizes and organizes your data, creating the foundation for automation and AI-powered business analytics, making data exploration accessible to everyone.
For instance, with ThoughtSpot’s Spotter sitting on top of your data warehouse, you can simply ask questions in natural language and gain instant insights. With real-time, automated answers at their fingertips, your teams can finally stay focused on driving the business forward.
3. Scalability without chaos
Growth doesn’t just mean more data; it means more demand for insight. As teams expand and questions multiply, your analytics need to scale just as fast. But that’s nearly impossible when every new request means overworked data teams and fragile data pipelines.
A strong data warehouse architecture brings order to the mess. It separates how data is ingested, stored, and accessed, giving you a scalable foundation that can grow with you.
Instead of constantly rebuilding pipelines or reengineering your data stack, you can add new sources, serve more users, and expand use cases without breaking what’s already working
Data warehouses have several functional layers, each with specific capabilities. Here are the most common ones:
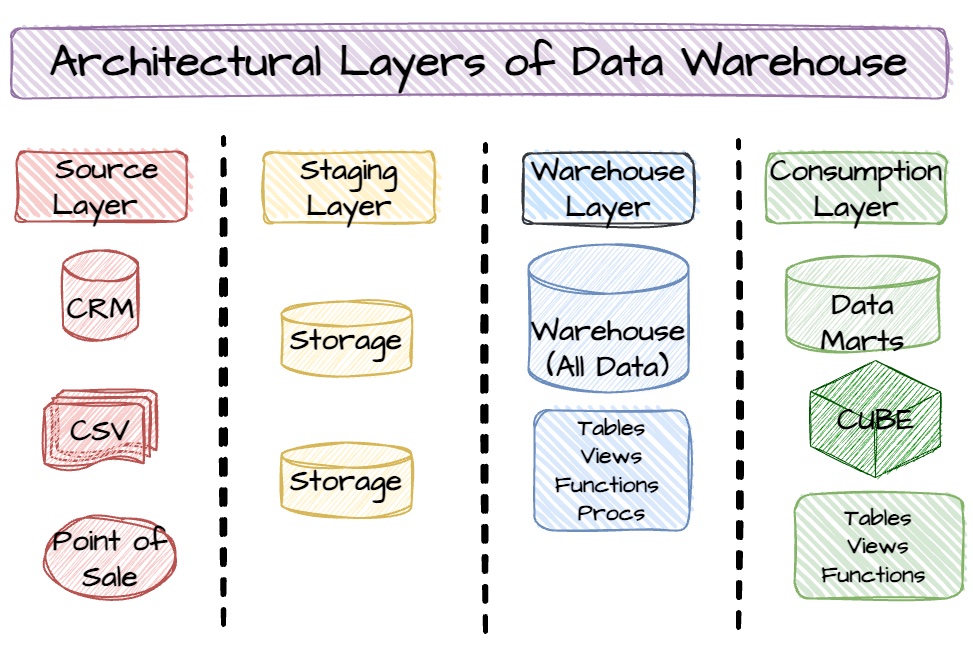
Data warehouses have several functional layers, each with specific capabilities. The most common data warehouse architecture layers are the source, staging, warehouse, and consumption.
1. Source layer
This is where it all begins. The source layer represents all your core business systems that generate and store raw transactional data. Think POS systems, CRMs, ERPs, marketing automation tools, and customer support platforms.
Each of these systems speaks a different "language" in terms of data structure and format. Because of this diversity, pulling in data from each source may require custom extraction or ingestion methods. Getting this part right is critical because it sets the foundation for everything downstream.
2. Staging layer
Once data is pulled from source systems, it lands in the staging layer. This is where data sits before it's cleaned, standardized, or transformed. Think of it like raw ingredients in a kitchen: they're not ready to be served just yet.
This layer is not meant for production use. The data hasn’t been governed or modeled, and using it for reporting can lead to serious inconsistencies.
3. Warehouse layer
This is the heart of the operation. The warehouse layer stores fully transformed, governed, and modeled data that’s ready for analysis. Here, the data becomes:
Subject-oriented (organized by business domain)
Integrated (standardized across sources)
Time-variant (historically accurate)
Non-volatile (stable and persistent)
Ultimately, this layer becomes the source of truth your teams rely on for accurate, consistent reporting.
4. Consumption layer
Also known as the analytics layer, this is where data insights come to life. Here, you expose warehouse data to end users, whether it’s data analysts running complex analysis, business teams analyzing churn patterns, or data scientists training predictive models.
The goal? Empower more people to explore data confidently, without needing to understand the technical structure underneath.
Every data warehouse architecture is made up of core layers, data processing workflows, and shared architectural components that support the entire system.
Here are those essential architectural components:
1. Data ingestion tools
Getting data into your warehouse is the first step, but it’s far from copy-paste. This is because different source systems produce data in different formats, at different frequencies, and with varying levels of quality.
Data ingestion tools, such as ETL and ELT systems, automate the process of extracting data from various source systems and loading it into your warehouse. They support both batch and real-time ingestion, often using connectors, APIs, or stream processing to move data efficiently from source to warehouse.
2. Transformation engines
Once raw data is in the warehouse, it needs structure. Transformation engines shape and clean that data, handling everything from standardizing formats to applying business rules and deriving new fields.
These engines can run transformations before data hits the warehouse (ETL) or afterward (ELT). Either way, they’re critical for turning chaotic source data into something analysts, tools, and business teams can actually work with.
3. Metadata management
Your warehouse is only as valuable as your understanding of what’s in it. Master data management gives you that clarity.
These tools maintain definitions, track lineage, and catalog datasets so users know where data came from, how it’s been transformed, and how it’s being used. This reduces duplication, avoids misinterpretation, and improves governance.
4. Orchestration and workflow tools
Data pipelines don’t run themselves. Orchestration tools coordinate the entire flow of data, controlling when jobs start, how they connect, and what happens if something breaks.
They make it possible to build repeatable, scalable processes for ingesting, transforming, and updating data. So instead of stitching together one-off scripts and hoping for the best, you get a system that runs reliably and adapts as your needs evolve.
5. Security and access controls
A data warehouse is a high-value asset—and a high-risk one if left exposed. Security and access controls define who can access what data and what they’re allowed to do with it.
This includes authentication protocols, encryption, role-based access control, data masking, and compliance policies. These safeguards help you balance data accessibility with privacy, regulatory compliance, and operational security.
6. Monitoring and logging systems
Even the best data systems break occasionally. Monitoring and logging tools help you catch issues before they become costly.
You can track everything from pipeline performance and job failures to usage patterns and system load. With the right monitoring in place, you can proactively spot bottlenecks and maintain a healthy warehouse environment that scales with your business.
Not every business needs a massive, complex data setup right out of the gate. The right data warehouse architecture depends on how much data you’re dealing with, how fast your business is moving, and how many people need access to insights.
Let’s walk through the three common types and when each one makes sense.
1. Single-tier architecture
This is the simplest setup. In a single-tier architecture, your data warehouse, ETL processes, and analytics all sit on the same layer. It’s a tightly coupled design that prioritizes speed and simplicity over flexibility.
When does it make sense:
You’re working with limited data or a single source system
You need lightweight, real-time analytics
You want something quick to set up and easy to maintain
Where it falls short:
Lacks data separation, making governance and versioning difficult
Limited flexibility in modeling or historical analysis
Not scalable for growing organizations
2. Two-tier architecture
Adds a bit more structure by separating data storage from data consumption.
A two-tier model is an architectural structure where data is first stored in a database (or operational data store), then accessed by analytics tools. There’s some transformation, but the structure is still relatively flat.
When does it make sense:
Mid-sized businesses that don’t yet need complex data modeling
Organizations just starting to centralize their data
Scenarios where low latency is more important than flexibility or governance
Where it falls short:
Hard to manage as data volume and complexity grow
Minimal separation between raw and modeled data
Governance, version control, and data lineage can get messy
3. Three-tier architecture
The gold standard for scalable, modern data platforms.
Three-tier architecture is a structured approach to building a data warehouse that separates data operations into three distinct layers: data ingestion and staging, data storage and modeling, and data access and consumption.
When does it make sense:
Easier to govern, maintain, and adapt over time
Supports advanced use cases like AI, predictive analytics, and self-service BI
Separation of layers makes it scalable and flexible
Where it falls short:
More complex to set up and maintain
Requires more tooling and expertise across each layer
May introduce latency between ingestion and insight if not optimized
1. Scalability can be expensive
Data warehouses can be costly to scale. On-prem solutions come with heavy upfront investments, while cloud platforms can rack up ongoing costs across compute, storage, and growing user demand. Add AI and advanced analytics to the mix, and expenses escalate quickly.
✅ Fix: Architect for scale from day one. Use tiered storage, compress large datasets, and monitor workloads to optimize performance without blowing your budget.
2. Skill gaps
Many business teams still depend on data engineers or analysts to pull even the simplest reports. When the data stack is too complex, insights become bottlenecked.
✅ Fix: Layer in intuitive, self-service analytics tools that sit on top of your warehouse, so anyone can explore and act on insights without writing SQL.
3. Separate systems for AI and BI
Most warehouses are built for reporting, not machine learning. That means AI and BI often run on separate systems, creating duplicated data and inconsistent results.
✅ Fix: Use a unified platform that supports both analytics and machine learning natively, so your teams can analyze, predict, and act in the same place.
4. Unstructured data
Modern business data isn’t just rows and columns. They also include PDFs, video, sensor logs, and more. Traditional warehouses struggle to accommodate these formats.
✅ Fix: Extend your architecture with a data lake or choose a cloud-native platform that blends structured and unstructured data seamlessly.
Escape the chaos of the data multiverse
Feel like you’re living in a data multiverse? You’ve got AI tools over here, analytics stack over there, and your data’s probably spread across multiple systems. None of it connects. And when you just want an answer, you end up lost in a maze of dashboards, pipelines, and reports.
It doesn’t have to be this way.
With ThoughtSpot, your data, analytics, and AI live in one connected ecosystem.
Whether you're forecasting, performing comparative analysis, or just trying to find that one metric buried in a dashboard, ThoughtSpot becomes a single source of truth that eliminates data silos, ensuring that every decision is based on the most complete and accurate picture of your business.
Bring order to the chaos. Start your demo today.
Frequently asked questions
What is data warehouse architecture
A data warehouse architecture is the blueprint for how data flows from source systems to decision-makers. At its core, it’s made up of multiple layers, which typically include data ingestion, storage, access, and analysis. The more layered it is, the more scalable and manageable it tends to be.
What are the four stages of data warehousing?
Data warehousing typically follows four key stages. First is data collection, where information is pulled from various sources like CRMs, apps, or databases. Then comes cleaning and transformation, where data is standardized and prepped for analysis.
In the storage stage, this clean data is loaded into a central warehouse. Finally, there's access and analysis, where business users and tools explore the data to make informed decisions.
What is ETL in data warehouse architecture?
ETL stands for Extract, Transform, Load. It’s the core process that moves data into your warehouse. Along the way, the data is cleaned, structured, and made ready for analysis, so you’re always working with accurate and reliable data.
What is OLAP in a data warehouse?
OLAP or Online Analytical Processing is how you slice and dice large amounts of data to answer complex business questions. It helps you analyze data across multiple dimensions such as time, region, or product, making it easier to spot trends, compare performance, or drill down into specifics.



