


You may already be familiar with dbt, but just to be sure we're on the same page, let's revisit the concepts. The Data Build Tool (dbt) is a widely used framework provided by dbt Labs, specifically designed to bridge the gap between data analysts, data engineers, and software engineers, resulting in the creation of a new role in data and analytics: the analytics engineer.
dbt Cloud’s core value proposition lies in enabling engineers to create more dynamic and reusable SQL and Python code. Coupled with Jinja, a templating language, it enables users to use control structures (like loops and conditionals), create reusable macros, and inject variables or expressions into their SQL functions and scripts, making the code more reusable, flexible, testable, and maintainable. All of these capabilities are further enhanced by the adoption of agile software engineering practices like version control, testing, and documentation.
With this shared understanding of dbt's capabilities, let's pivot to how you can maximize the benefits of your dbt instance.
Use pull requests in your workflow
Modern version control systems (VCS) like GitHub, GitLab, and Azure DevOps do more than just track changes to source code. They use pull requests (PR), sometimes called Merge Requests (MR), to promote code reviews, reduce errors, and increase collaboration. A PR is a request to merge code changes from one branch of the code repository to another, usually from a feature-specific branch to a version-specific branch or the master branch. It is an essential part of collaborative development and code review workflow.
Source code management policies differ between organizations, as such, the version control systems are configurable for the full spectrum of source code management (SCM) policies, from lightweight to tightly governed. Customize your policies for your organization but don’t leave out the pull request.
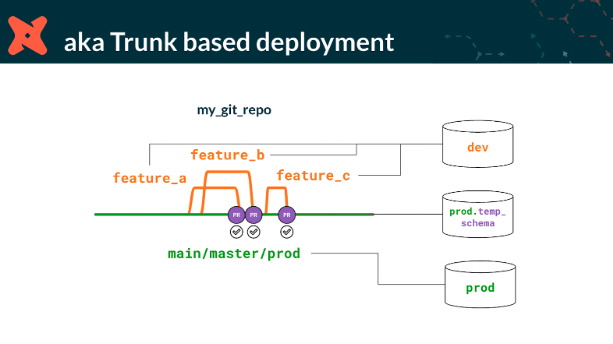
Here’s a typical workflow:
Create a feature branch. When analytics engineers want to make changes or additions to their dbt code base, they first need to create a new branch in the repository. This enables them to make their changes without disturbing the main code base.
Implement the code changes. Analytics engineers make their code changes in the newly created branch, save and commit the changes with an explanatory description, oftentimes with a ticket number.
Open a pull request. When engineers are ready to have the code peer reviewed and accepted, a PR is created. This is a request to 'pull' or ‘merge’ their changes into the main branch.
Review the changes. The PR is a space for team members to review the proposed changes, discuss potential modifications, and even add further commits if necessary. Automated checks can also be run to ensure the new code doesn't contain any errors and aligns with the project's standards.
Pro Tip: Create a PR template that defines pre-conditions and post-conditions, like coding standards, integration tests, and reminders.
Merge the pull request. Once the code is verified and validated and all concerns are resolved, the pull request can be merged. The code is then merged into the main branch.
Delete the feature branch. After the merge, the feature branch where the changes were made can be deleted, keeping the repository clean.
The real magic happens in steps 3, 4, and 5. This is where data teams get to share experiences, junior analytics engineers learn, teamwork grows, and errors are resolved before they get into production.
Set up automated testing in your CI/CD
dbt Cloud supports continuous integration and deployment (CI/CD) principles for your code deployment pipelines. Automated testing and CI/CD should be coupled with your version control system and pull request.
Set up automatic testing for your dbt models. Tests can be simple schema tests that evaluate uniqueness, data validation tests that ensure data quality or complex logic coded in dbt packages like dbt-expectations. In all cases, when you change your code base, dbt Cloud will automatically test your code to ensure there are no unintended side effects or defects. Integration tests like these will ensure you identify and address problems early, saving you from costly errors in the future.
models/orders.yml
version: 2
models:
- name: orders
columns:
- name: order_id
tests:
tags: [order_unique_tag]
- uniqueSimple uniqueness test example.
The integration with the version control system makes this process seamless. In the example below, dbt Cloud is utilizing GitHub’s pull request process, so you have a consistent workflow across your organization.
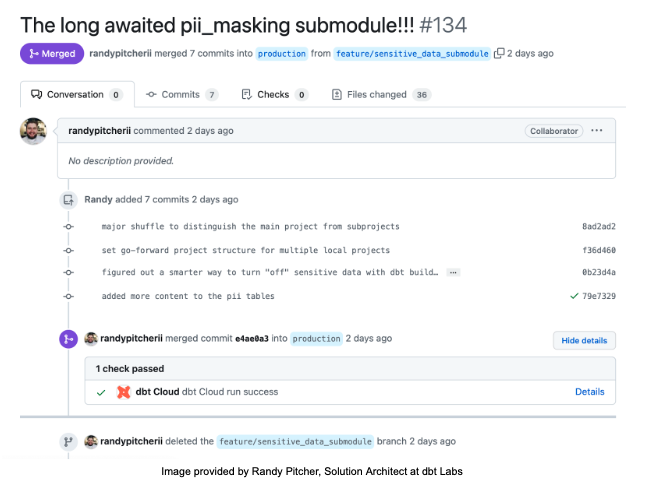
When the PR is created, dbt will build the data to a temporary schema in the cloud data warehouse, load the data, and run your integration tests, thus ensuring that you deliver quality code and data. Not to worry, once the pull request is closed or merged, dbt Cloud will delete the temporary schema and data from your data warehouse.
Start Getting Better Insights
Maintain and utilize data lineage
dbt provides data lineage capabilities for understanding and visualizing your data lineage–that is, tracing the journey of your data from its raw form to its final transformed state. By actively maintaining and making use of this feature, you can gain a better understanding of your data transformations, identify potential issues early on, and ensure that your data remains trustworthy and reliable. This is particularly valuable for complex data models where it can be challenging to understand the dependencies between various models, aggregates, and metrics.
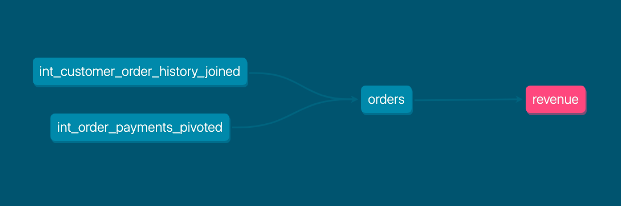
The power of dbt comes from its coding capabilities, so make sure you and your data team are comfortable with SQL, Jinja, software engineering, and the principles of data modeling. Additionally, take advantage of the online documentation dbt provides; it's a powerful tool for learning dbt best practices and troubleshooting any issues.
Now you can fully leverage your analytics data
Increased speed to market, greater collaboration, and higher quality data all start with the fundamentals of analytics engineering. I’ve shown you a few tips on how to get the most out of your dbt Cloud instance. Next, you’ll need to scale the impact of all that data by getting insights into the hands of business users and analysts.
With ThoughtSpot, technical and non-technical users in your organization can drill into the data, ask their own questions, and find new insights. ThoughtSpot delivers AI-Powered Analytics, fueled by natural language processing, to make self-service analytics available anytime, anywhere.
Get started on your analytics journey by signing up for a 30-day free trial of ThoughtSpot today.
Special thanks to Randy Pitcher, Solutions Architect at dbt Labs, for the images and PR. His demo code is available on github.
Sonny is a Senior Analytics Evangelist at ThoughtSpot where he leverages his data expertise and Snowflake Data SuperHero experiences to enable customers, provide thought leadership, and drive product innovation. He is an early adopter of cloud data analytics platforms and a hands-on data leader with deep experience in data engineering, advanced analytics, and the modern data stack. Although his data journey has taken him to some leading companies such as Ally Financial and AAA, he is also an entrepreneur and founder of two companies. Sonny is a multi-time presenter at Snowflake Summit.



