


Organizations across all industries are racing to understand large language models (LLMs) and how to incorporate the generative artificial intelligence (AI) capabilities provided by LLMs into their business activities. Thanks to LLMs’ broad utility in classifying, editing, summarizing, answering questions, and drafting new content, among other tasks they are being embedded into existing processes and used to create new applications and services. According to McKinsey & Company the annual economic benefits when applied across industries could be $2.6 trillion to $4.4 trillion annually.
What are large language models (LLMs)
Large language models are a subset of machine learning called deep learning, and are used to power generative AI applications like ChatGPT, Google Bard, and many others. The models have many deep layers of neural networks that are modeled on how neurons are connected in the human brain. Through training they learn about patterns in language, and then given some text, they predict what text should come next. For example by entering, “once upon”, an LLM might respond, “Once upon a time, is a classic way to start a story”. Or it might write a story starting with “Once upon a time.”
Large language models costs
While individuals experiment with the free versions of LLMs, understanding the cost of using an LLM for a business application like a customer support chatbot can be complex. LLM providers charge based on the number of tokens, which are units of text characters—like a word. To get a sense of how many tokens are in a block of text, you can use a tokenizer. This paragraph is 90 tokens based on how OpenAI defines a token.
Using pricing models from Azure’s OpenAI Service pricing page you can see there is a great deal of variability in costs ($0.0004 to $0.10) per 1000 tokens depending on which model you are using. Part of the pricing variability is the result of different models having different limits on how many tokens (2048 to 32,768) the model can retain in memory for the task in the chat conversation. And if you want to use one of the GPT-4 models, pricing gets more complex with different Prompt and Completion token costs. Given this pricing complexity we are already beginning to see organizations struggle with how to use LLMs effectively and affordably.
Start Getting Better Insights
Applying the lessons learned from cloud computing to large language models
Organizations made massive investments in cloud computing during the last couple of years as part of their digital transformation initiatives. No upfront capital expenditures, fast and easy setup, ubiquitous availability, and elasticity of computing resources supported the need to quickly adjust to rapidly changing business conditions. The immediate focus was on the technical requirements of moving to cloud, revamping business processes, and the impact to on-premises data centers.
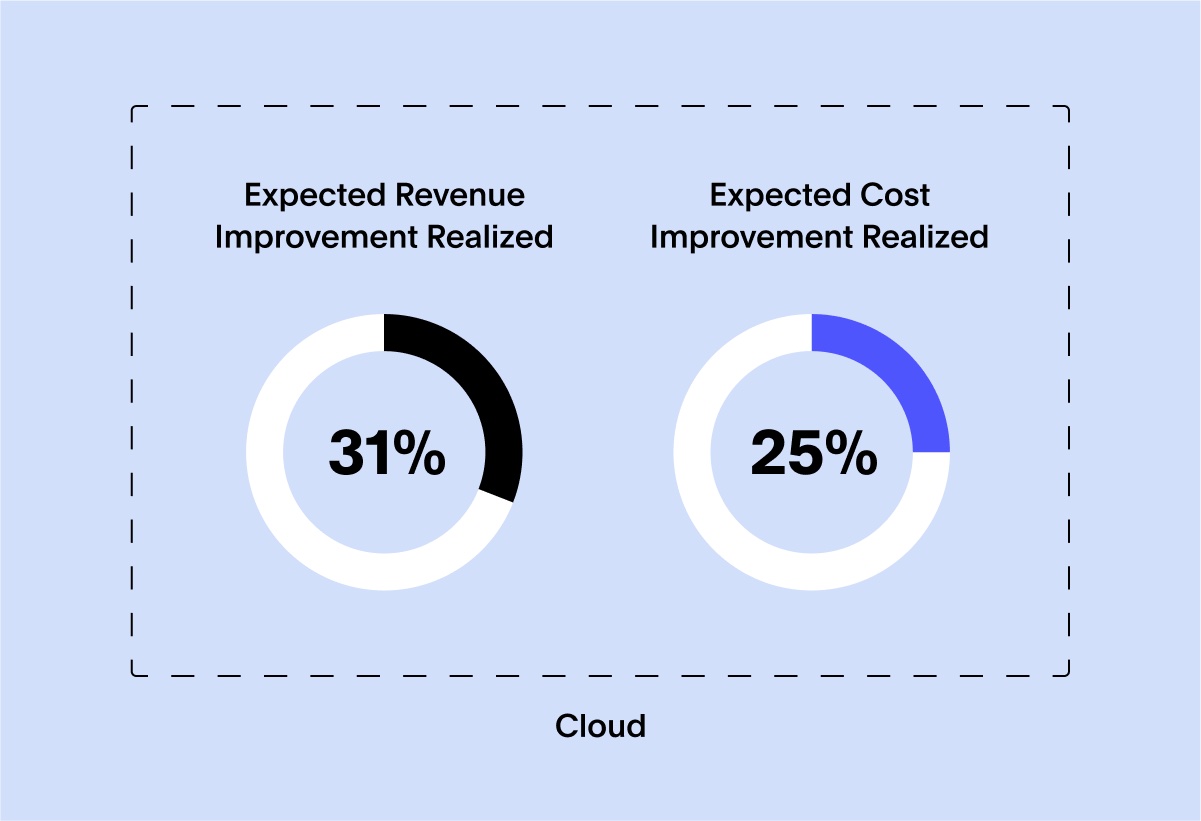
Yet a report by McKinsey found that on average, organizations have realized less than a third of the benefits they expected. And a second report found that only 15% of organizations can establish a clear relationship between their investments in the cloud and the delivery of business value. One culprit os a lack of visibility into and predictability of what resources are being consumed until the bill shows up.
Multiple teams and functions across organizations, like DevOps, data engineers, and data scientists, are purchasing cloud resources without checking in with IT or procurement to see what contracts already exist. And they are being purchased on multiple cloud platforms using multiple pricing models. This can lead to poor visibility of spending, inaccurate forecasts, and inefficient operations.
The response from executives to the lack of visibility and higher-than-expected cloud bills has been a mandate for more robust cloud cost management. And today the practice of cloud financial operations, or FinOps provides a practical framework for monitoring, measuring, and managing cloud resource consumption that can be applied to large language models.
What is FinOps
FinOps is a vital financial management practice that helps organizations get more business value from cloud investments. It uses a multidisciplinary approach that requires collaboration between technology, business, and finance teams to balance cost, usage and organizational needs to optimize the value realized from cloud computing. According to Boston Consulting Group, FinOps can deliver 20% to 40% savings on monthly cloud costs. These savings can fund innovative use cases and create new revenue streams.
The three phases of FinOps
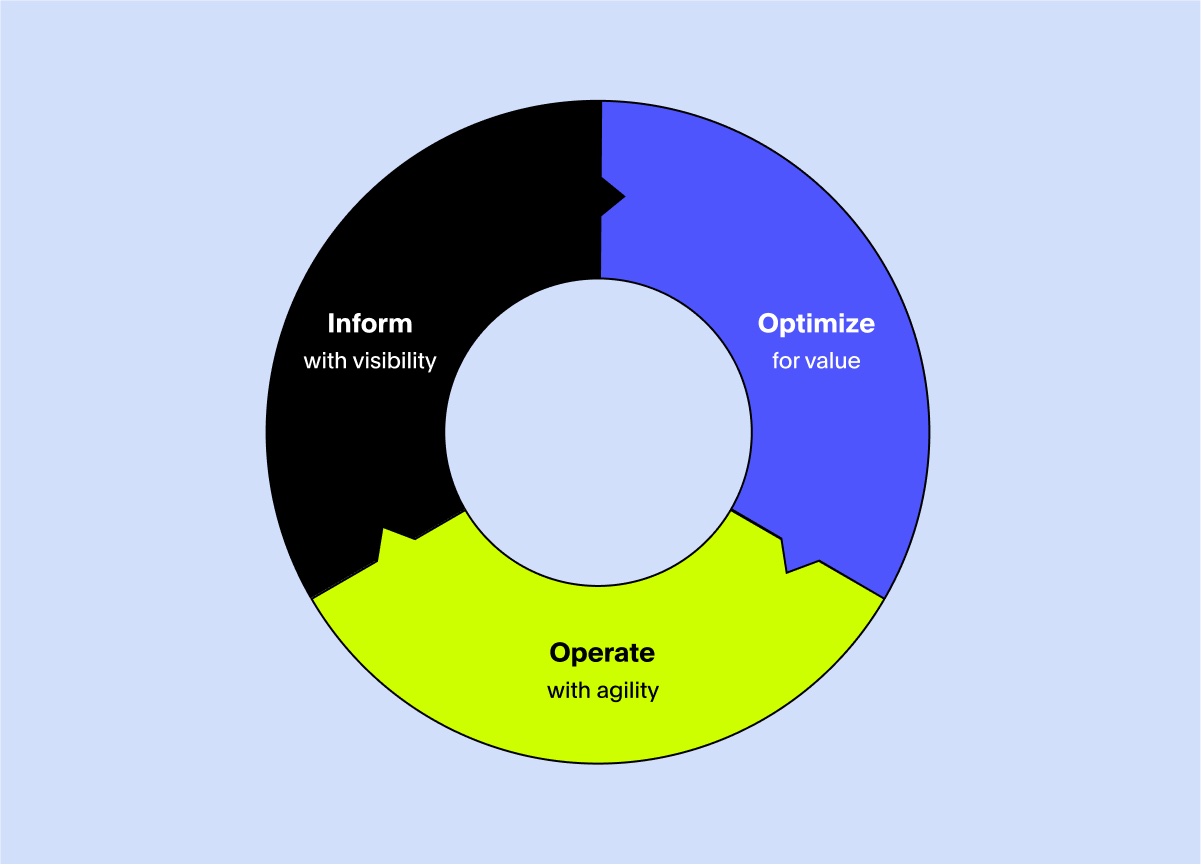
FinOps uses the concept of a continuous lifecycle for deployment and optimization found in other practices such as DataOps (data operations), MLOps (machine learning operations) and DevOps (development operations). The FinOps Foundation outlines three phases to guide organizations in their establishment of a FinOps practice, as well as the day-to-day activities to support the practice: inform, optimize, and operate.
Inform
The inform phase centers on providing visibility for all stakeholders on what kinds of databases, analytics and application workloads are running in the cloud and their associated costs. It also centers on which teams and business units are running the workloads, and on which cloud ecosystems. Transparency into how cloud resources are being consumed is foundational to business value realization.
Optimize
The optimize phase revolves around forecasting and planning cloud use to reduce costs and maximize business value. This includes reducing both over- and under-utilization of current resources, as well as modeling the need for new resources based on business projections. Creating scenarios regarding compute, storage, network, and managed database services can help you identify ranges of potential impacts and outcomes so you can adapt faster and with more confidence.
Operate
The operate phase focuses on the day-to-day activities required to manage and govern cloud infrastructures. Both you and your teams need to understand how to utilize various levers like scheduling, auto scaling, reservations, and spot instances, as well as reducing data transfer and exchange. These levers, combined with guardrails for lean and automated provisioning, can help you improve the value realized from your cloud resources.
FinOps for large language models
By utilizing the Inform, Optimize, and Operate phases of FinOps, organizations can more effectively manage costs and maximize the value of large language models. This entails gaining visibility into LLM usage, improving forecasting and planning of future needs, and employing techniques to actively manage usage and cost. Let’s look closer at how to apply the FinOps phases to LLMs.
Inform
Here are a few approaches to achieve visibility into the use of large language models:
Usage tracking: Implement mechanisms to track the usage of LLMs, including the number of queries processed, the size of prompts used, and the frequency of API calls. Data collection can be achieved through logging and monitoring systems.
Cost attribution: Establish a system to attribute costs associated with LLM usage to specific teams, projects, or business units. This involves employing tagging to facilitate mapping LLM usage to relevant entities within the organization.
Reporting and analytics: Integrate LLM usage and cost information into your current FinOps reporting and analytics processes. That way, stakeholders have a consolidated view of all cloud resources and associated costs, including LLMs.
See how ThoughtSpot can inform your LLM FinOps with interactive, AI-Powered Analytics—start a free trial.
Optimize
Here are a few approaches to optimize the use of large language models:
Demand forecasting: Work with stakeholders to understand expected use cases for LLMs. This information helps in making informed decisions regarding usage growth, required model capabilities, and capacity planning for future demand.
Right sizing: Different LLM models have varying capabilities and limits, such as the number of tokens they can process or retain in memory. Understanding mechanisms like key-value caching, usage patterns, model capabilities, and pricing can help you select the most suitable model for your specific use case.
Scenario planning: The LLM market is still in its early stages of development and changing rapidly. It will be important to monitor how capabilities and pricing evolve and model the cost implications and performance trade-offs for various use cases.
Operate
Here are a few approaches to actively manage the day-to-day use of large language models:
Prompt adaptation: Reduce prompt size by removing unnecessary information and curating a smaller set of relevant examples. Also providing context in prompts, such as explicit instructions or constraints improves response generation, and reduces the number of prompts needed to get the desired output. We saw the need for specific instructions in the example earlier of different responses to the prompt “once upon.”
Completion cache: You can reduce the need to invoke the LLM API multiple times by storing responses in a local cache that is then used to answer similar queries. This can provide significant cost savings—particularly in scenarios where similar queries are frequently posed, like support chat bots. Third-party libraries like GPTCache or LangChain provide a simple API for storing and retrieving LLM completion results, or you can build your own solution for more flexibility and control.
LLM cascade: An LLM router sequentially sends prompts to different LLM APIs that are sorted by cost. A scoring function determines if the response is acceptable. Once an acceptable response is obtained, no further LLM APIs are queried. This approach enables you to use the most cost-effective model to perform the task requested by the prompt.
These are just a few examples of how to use the Inform, Optimize, and Operate phases of FinOps to manage costs and maximize the value of large language models. Other techniques like model fine-tuning for a specific use case and query concatenation can also be used. As this space evolves, it’s important to network with peers, sharing lessons learned and best practices.
Get a head start of FinOps for LLMs
Unless you establish oversight and accountability, the rush to use large language models will lead to excess spending. Fortunately, you don’t have to reinvent a framework for monitoring, measuring, and managing usage and costs. FinOps can help you increase visibility of LLM use and spend, optimize business value realized from LLM investments, and actively manage resource consumption across your organization.
Don’t wait until a big bill comes due to effectively and efficiently manage LLM use. Start now by addressing the top FinOps initiatives:
Create visibility and transparency of LLM usage and costs
Establish best practices for LLM reporting and forecasting
Integrate LLM use and cost data into existing reporting
The bottom line? FinOps for large language models delivers more business value at a lower cost. That’s what I call a win-win.



