


When was the last time you took an online survey? Or maybe you answered a poll on LinkedIn, giving a creator insight on a certain topic. While this is what many think of when they hear the words data collection, an entirely different topic may come to mind when you ask a data engineer. Instead, a data engineer probably thinks about all of the different data collection methods they can use to move data from point A to point B.
Either way, data collection is an important process for understanding anything! Whether it's the opinions of your users or the success of a new product launch, data collection is the first, and arguably most important, step in the analytics process.
Table of contents:
Data collection is the process of gathering and validating data that will allow you to find trends and insights that answer business questions. For data engineers, it consists of finding the right tools to help bring the data into your cloud data warehouse. After all, many different external systems like Google, Facebook, Hubspot, and Shopify generate key customer data that businesses depend on. And that is just in addition to the extensive data produced by your own internal application or site!
Why data collection is important
Data collection plays a big role in how high the quality of your data will be. You need to ensure you are getting accurate data from reliable sources before you can actually analyze and hand off data to the business users. I always say, junk data in equals junk data out. Your analysis is only as good as the quality of your data, so you better make sure you are keeping it high!
For data engineers specifically, collecting data is the first step when setting up a data pipeline. Collecting the data using reliable tools and methods helps analytics engineers and data analysts that depend on these sources know they are working with reliable data. The raw data ingested by data engineers is often the initial source of truth for all data teams, as such, data integrity and trustworthiness are crucial. Because data teams compare the results of their models and the calculations used in their dashboards to the raw data that was initially collected.
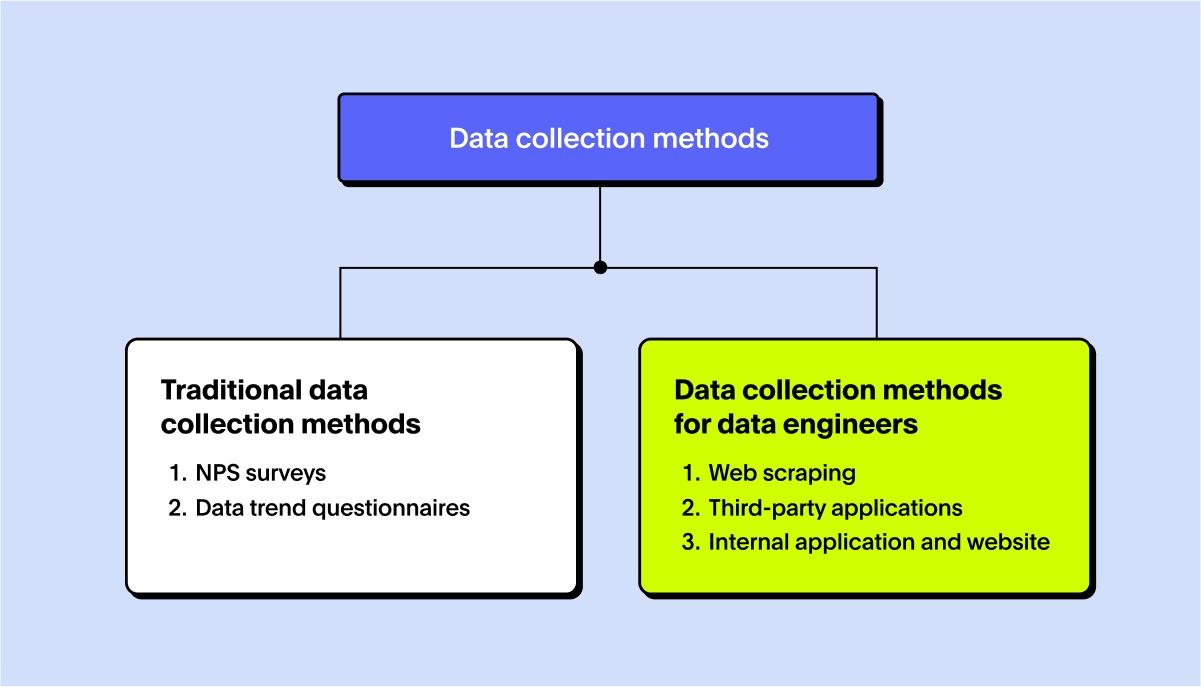
When you think of data collection, you may think of the definition you learned in a high school or college statistics course. I distinctly remember multiple choice questions on the SATs asking about the different data collection methods. In these classes, you probably learned about methods like surveying, interviewing, focus groups, and questionnaires. However, I’ve found these to be rare in my experience as an analytics engineer.
Sure, we occasionally will use surveys to gather thoughts from customers and better create products that serve them, however, this isn’t a common occurrence.
1. NPS surveys
In one of my previous roles, we used something called NPS, or Net Promoter Score, to measure how satisfied customers were with our product/service. This is a common KPI used to measure overall customer experience and customer loyalty to a brand. NPS can only be measured by a single-question survey where a customer ranks how likely they are to recommend the company on a scale of 0 to 10.
This data is typically collected using some type of survey platform like Qualtrics or SurveyMonkey that you can easily integrate into company emails. Then, customers receive a prompt to answer this one question every 3 months or so. As a data engineer, I ingested this SurveyMonkey data from the application to our data warehouse using Fivetran. Once it was in the data warehouse, the data analyst was able to create a dashboard that updated hourly, allowing the business to keep close tabs on this KPI. The power of data collection!
2. Data trend questionnaires
This is a type of questionnaire put out by data companies to help grasp the trends of the market. I’ve seen Airbyte and Census promote this type of survey a lot in the past 6 months. Luckily, these results are often made public to everyone in the industry, becoming a good data collection source for other data companies as well.
These questionnaires help the company understand where to steer its efforts and also help the larger data community. They often ask questions about where you see the industry going, your favorite tools, and the biggest problems you face. I personally enjoy reading the results of these questionnaires because it lets me know what topics people are interested in learning more about in the form of blog articles, but also which modern data stack tools are most favored!
There are three main ways to collect data as a data engineer—web scraping, third-party applications, and internal applications.
1. Web scraping
Web scraping entails using some type of bot to “scrape” data in the form of text from different websites. This form of data collection is becoming more popular in order to get information about customers that you may not explicitly ask them for.
For example, customers may provide you with links to their different social media pages. This is a powerful asset for sales and marketing teams because they will likely want to know about the social media behaviors of their customers. With web scraping, they can then collect public information from social profiles. For example, you might want to know the number of people someone is following, how many times they have posted, or how many followers they have.
With web scraping, think about data that is easily available on the internet, but maybe not directly through your own account on that application. For example, you can’t see information about someone else’s followers by looking at the analytics on your Instagram account. However, you can go to someone’s direct profile and see that information publicly.
If using web scraping as a method for data collection, keep in mind that it is very error-prone. This is probably one of the most unguaranteed methods in terms of data quality. While some web scrapers are great, there is always the possibility of errors. For example, the system could tell you that someone is following 3.1 people, despite you knowing this can’t be possible. Using a web scraping proxy can help mitigate these challenges by improving data retrieval consistency and avoiding IP bans, ensuring a more reliable collection process. Consider all of the possible data quality metrics and issues while implementing tests and data cleaning functions to prevent these problems as close to the data source as possible.
2. Third-party applications
Third-party applications refer to the platforms like Jira, Calendly, and Shopify that provide application programming interfaces (APIs) and are deeply ingrained in a business. They are the tools used by the sales, marketing, finance, and growth teams, making them extremely important to integrate with other areas of the business. Ideally, you collect data from these tools and ingest them into the data warehouse along with the data from all of your other sources to create a single source of truth. With these applications, you can use 3rd party tools like Airbyte and Fivetran that call this APIs and allow you to schedule ingestion on a regular basis.
Third-party applications have a lot of data collection and tracking methods available directly within the tools themselves. However, because it’s not data you directly own, you don’t always have control over what data is collected or not. The data available depends on the application itself. For example, you may want data about a specific table in Stripe, but if Stripe hasn’t made that data publicly available for businesses to query, you won’t be able to access it.
Similar to web scraping, it can be hard to validate the data coming from these applications. However, this data is valuable because it helps you validate data across your internal system and other tools. I recommend creating data models that compare multiple metrics with the same definitions from different data sources so that your results stay consistent across different applications. For example, consider your Shopify data. By comparing the number of orders placed on your website for a certain date with the number of orders being sent out of your warehouse, you ensure the quality and accuracy of your data—lead
3. Internal application and website
The main method of data collection for any business is typically the collection of data on its own application or website. With this type of data collection, it’s important to work with engineering teams to ensure everything is tracked in a way that is usable by analytics engineers and data analysts. Communicating with engineering teams is typically the biggest struggle of a data engineer, as it involves clear communication and understanding one another’s needs. While it is best to set very specific expectations from the very beginning, most data engineers don’t have this luxury.
When an application or website has been around for a long time, there is a good chance that the data has been collected in a way that no longer makes sense. The system in place may be a legacy way of doing things with a number of cracks and holes—it’s up to the data engineer to patch them up. When joining a new company, don’t assume the data being collected from the company’s own application is correct. Joining as a new employee is the perfect opportunity to kick the tires on the current data collection systems, looking for opportunities to create better solutions and quickly add value in your new role.
When I joined a previous team of mine, I found holes in the website’s data that have existed since the very beginning. However, since the other engineers were working with that data for so long, they were blind to it. I was able to shed new light on these problems—explaining why we needed to address the issues in order to strengthen our analytics strategy.
One particularly common issue with legacy systems involves the tracking of historical data. While on this team, I found historical records that were being overwritten due to the way products were being manually entered into our system. This caused all of our historical data to be inaccurate—reflecting the details of currently stocked products rather than the products that were actually sold at that time. If you run into this type of issue, be sure to look into slowly changing dimensions and how historical records should be properly tracked over time in your database.
When collecting data for analysis, it’s important to keep the following things in mind.
Never assume anything
When joining a successful company, it’s easy to assume all of the current ways of doing things are correct. However, when it comes to data, this is rarely the case.
There is always going to be something wrong or one thing that can be vastly improved. This process requires thoughtful exploration and thorough understanding of data systems—you never know where you will find gaps in peoples’ knowledge or systems. While this is especially true for internal applications, you also want to question third-party application data, as these data sources could also be set up in a way that’s not conducive to the business.
Main take away: Question everything, get differing opinions, and always try to improve what already exists!
Always validate
I can’t tell you the number of times I assumed the numbers in a dashboard were correct or that a certain KPI definition was the best way of finding a certain metric, only to discover weeks later that the data was incorrect. When collecting data, you need to validate that data source in as many ways as possible. You can do this using various validation methods like comparing metrics to those on the UI, cross validating with a trusted external system, and comparing to common industry benchmarks.
Don’t depend on a single data collection method. Validate new data sources against older, previously validated data sources. If KPIs vary across different sources, there is no true single source of truth. This will prove problematic for your entire analytics environment. It’s always best to fix these types of issues early on rather than when stakeholders are already reliant on a data source.
It’s also important to note that data collection itself can be the source of data integrity issues! Problems don’t always root in the data and transformation processes but the different methods used to collect the data or the data pipeline itself.
Main take away: Wherever possible, make sure you compare similar data sources to ensure they both deliver the same metric.
Ask yourself, how is this being used by the business?
When collecting data, you also want to think about the grander purpose. You aren’t collecting data just to have it sit in your data warehouse—taking up precious resources and running up costs for the business. Data is supposed to be used to make better business decisions.
Whenever you collect a new data source, ask yourself, “How will this affect how the business makes decisions?” Answering this question will help you prioritize the most important aspects of the data. It will also lead you to validate your data in a way that makes the most sense.
The last thing you want to do is collect inaccurate data that leads stakeholders to make all of the wrong decisions. After all, “decisions based on bad data are just bad decisions that you don’t know about yet”. At the end of the day, you want to prioritize data collection methods that will have the most positive change on the business.
Main take away: Always keep the why in mind when collecting data. This will steer you down the right path.
When it comes to data engineering, the idea of data collection has quickly evolved. And it will only continue to evolve further! While traditional methods like surveys and questionnaires are still used in specific scenarios, they aren’t used as often as internal applications, third-party applications, web scraping services, and event tracking. Data collection in the context of data engineering is more than simply gathering data from different sources and ensuring it ends up in the data warehouse. It’s about guaranteeing this data is as accurate and reliable as possible—creating a single source of truth for analytics teams and their business stakeholders.
When it comes to data collection, data engineers need to focus on asking tons of questions, validating all of the data that they bring in, and thinking about it in the larger context of the business. When this is done properly, data collection becomes one of the most important steps in the data pipeline.
The best way to get the most business value out of the data collection process is by ensuring those data points and insights are available to you frontline decision makers. By allowing users to search data in natural language and drill down into Liveboards to find granular details and AI-powered insights, ThoughtSpot empower businesses to realize the value of their data. Start your 30-day free trial today, and put generative AI to work on your business data.



