


I’ve encountered a thousand different problems with spreadsheets, data importing, and flat files over the last 20 years. While there are new tools that help make the most of this data, it's not always simple.
I’ve distilled this list down to the most common issues among all the databases I’ve worked with. I’m giving you my favorite magic fixes here. (Well, okay, they aren’t really “magic” but some of them took me a long time to figure out.)
Problem 1: I need a tool to make this easier.
CSV Kit is the best utility that I’ve found for working with CSV files.
It’s a free set of tools for dealing with CSV files on Linux. Some of the cool things it can do are:
CSV clean will validate and clean the file of common syntax errors. It isn’t magic, but can definitely help.
CSV grep is incredibly useful. It’s similar to UNIX grep but optimized for CSV files. It can do a grep on just certain columns, for example.
CSV SQL will generate a CREATE TABLE SQL statement based on the file. How about that for jumpstarting your DDL? It helps because you usually don’t get the corresponding DDL with the CSV file.
Problem 2: I'm running into character set conversion errors.
You can use the uconv program to solve errors with character set conversion.
iconv comes with most UNIX OS distros, but uconv does not. iconv is limited by memory. uconv is much better for working with large files. Use app-get or another UNIX package manager to get uconv if you don’t have it. Then issue a command like:
uconv --from-code ISO_8859-1 --to-code UTF8Start Getting Better Insights
Problem 3: What are these extraneous control characters doing?
Sometimes a file looks fine, but doesn’t load. It could contain non-printable ASCII characters that usually don’t belong in CSV files. It can be hard to track these down. You might have this problem if you get some unusual error messages when you try to load the file, and you can’t trace it to another cause.
You can use this Perl command to strip these characters by piping your file through it:
perl -pi.bak -e 's/[\000-\007\013-\037\177-\377]//g;'Problem 4: I don't know how to approach NULL values.
Make a conscious choice about how you want to handle NULL values. Typically you can use \N to represent NULL values in the data. And if you have empty strings, you can use two successive delimiters (like ,,) to indicate that the field contains no data.
Note that Postgres has some problems with importing these types of files when they contain NULL values. Postgres will not let you specify a NULL value as an empty string (,,). That’s usually a fine way to represent NULLs, but it won’t import properly as a NULL in Postgres. You must use an explicit NULL designator like \N, so if you really care about NULL values, you should make it a practice to use \N.
Whatever you decide, make sure it’s a conscious decision. Otherwise you may be surprised when you import the data and you get a bunch of empty strings where you were expecting NULLs.
Problem 5: I'm seeing incompatible line return characters.
This one is hard to track down. If all else fails, try opening the file with vi. Do you see some weird characters like the blue ^M characters in this example?
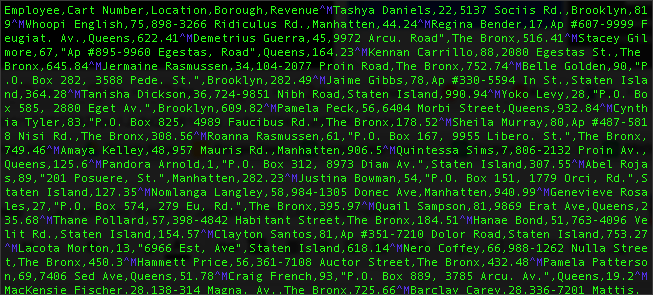
If so, the file was saved from a PC or Mac instead of Linux/UNIX. You've got four options to fix this:
1. You can open the file in a text reader and save it again with the UNIX line breaks.
2. You can use a utility like fromdos or dos2unix to convert the file.
3. You can use a vi command like this to replace the line breaks with the correct ones: :%s/^M/^M/g
Hint: The trick here is in how you enter the command. For the first ^M you need to hold down the Control key while typing vm. For the second one, type Control + v and then ENTER.
4. Sometimes your file will be too large to open in vi. In this case you can use sed or tr as described here.
Those are the top six issues I’ve encountered whether working with data from Oracle, SQLServer, Teradata, or an Excel file from someone’s desktop. Sometimes you won’t even know the source of a CSV file you need to load. But these tricks will help you get your data into a form you can use, no matter the source.
Interested in swapping the manual data fixes for an easier spreadsheet analytics solution? Try out ThoughtSpot for Sheets or ThoughtSpot for Excel. Now, you can visualize your data and find AI-powered insights in the workplace tools you're already using.
Psst! Be sure to check out parts one, two, and three of our CSV blog series.



