

Kubernetes is one of the hottest open-source projects these days. It’s a production-grade container orchestration system, inspired by Google’s own Borg and released into the wild in 2014. Thousands of developers joined the project since then, and now it’s becoming an industry standard for running containerized applications. Kubernetes is designed to run production workloads on a scale, but it’s capable of much more. In this article, I’ll talk about my experience setting up a Kubernetes cluster as a core component of a development infrastructure while working at ThoughtSpot.

Context
ThoughtSpot is developing a sophisticated BI system for large enterprises, which runs on top of another Borg-inspired orchestration system called Orion. It was designed internally, at the times when neither Docker nor Kubernetes were publicly available.
A few things to know about ThoughtSpot, which are relevant to this article are:
The system consists of a few dozens of services and the overhead of running them all is quite massive. Idling system with very little data requires 20–30Gb of RAM, 4 CPU cores and 2–3 minutes to start up.
ThoughtSpot sells its own appliance, typically with at least 1TB RAM per-cluster, so that 20–30Gb overhead is not a problem for the product. However, it’s quite an issue for the dev infrastructure.
There’s a lot of retired hardware available for developers in the office.
Motivation
I was initially assigned to solve an easy-sounding problem: make integration tests faster. There were a few hundreds of Selenium-based workflows, which were running sequentially and taking up to 10 hours to complete. The obvious solution was to parallelize them. The problem was that they were not designed to run concurrently and hence we had to either refactor all tests or provide an isolated copy of the ThoughtSpot system (a test backend) for every thread to run on. Redesigning tests might look like a cleaner solution, but it would require a tremendous effort from the whole engineering team and a lot of test-related changes in the product, so it was not feasible. We’ve decided to take the second approach, and that left me with the task, I’ve ended up solving with the help of Docker and Kubernetes: make it possible to quickly (in 2–3 minutes) spin up dozens of test backends with pre-loaded test data, run tests, tear them down, repeat.
The path
With this task in mind, I started looking for options. Actually, some infrastructure was already in place: we had a VMware cluster running on four servers. Current integration tests were already using it for provisioning test backends, but there were problems:
It could only sustain about one hundred VMs, after that we would have to buy more of the expensive proprietary hardware. It was already utilized for about 80% by other workflows in the company.
Cloning 10 or more VMs in parallel was blowing up the IO. It would have to move around ~500Gb of disk snapshots, and it was taking forever.
VMs were taking way more than 2–3 minutes to start up.
Virtualization wasn’t a viable option for us, so we turned our heads to containers. In early 2016 we were looking at two main options: LXC/LXD and Docker. Docker was an already recognized leader, and LXD 2.0 was only going to be released along with Ubuntu 16.04. However, Docker has a strong bias towards small, single-process containers, which have to talk to each other over the network and form a complete system in this way. LXD, on the other hand, offered something, that looked more like familiar VMs, with the initsystem and the ability to run multiple services inside a single container. With Docker, we had to either compromise on the cleanliness and use in an “LXD way” or re-factor the whole system to make it run on top of Docker, which was not feasible. On the other hand, with LXD we could not rely on the exhaustive community knowledge, as well as the documentation, that Docker had. Still, we’ve decided to give it a shot.
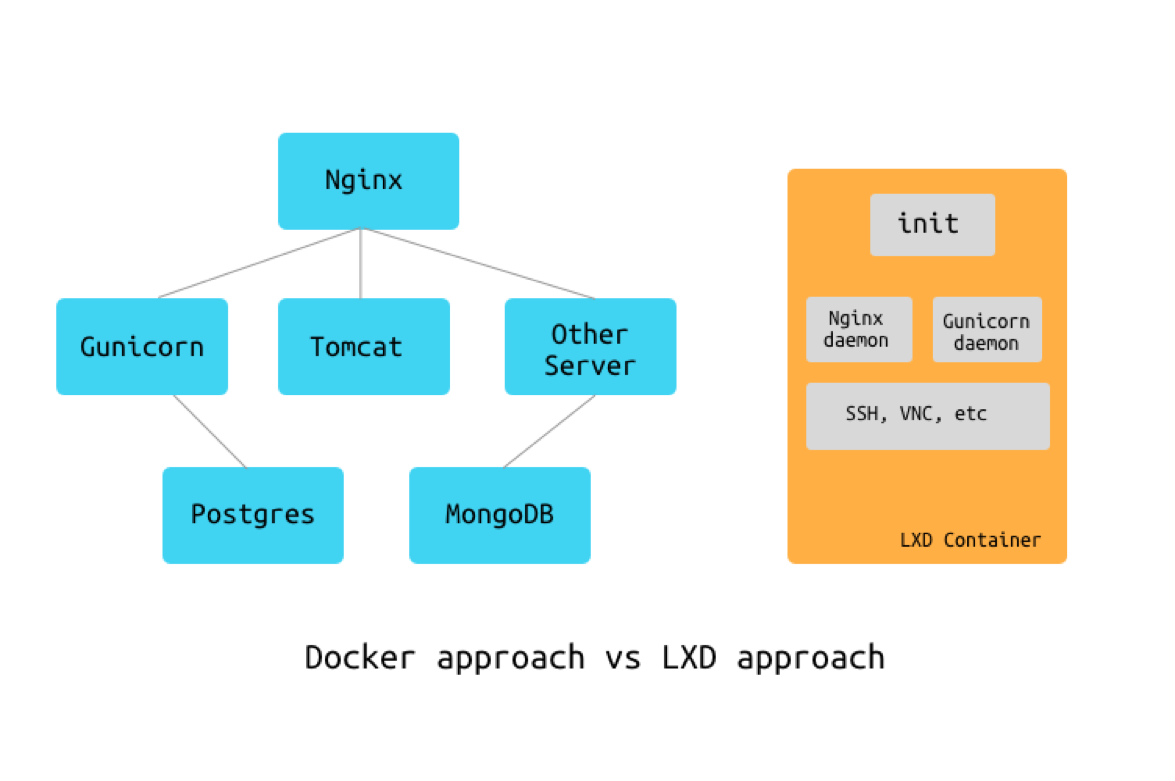
LXC/LXD
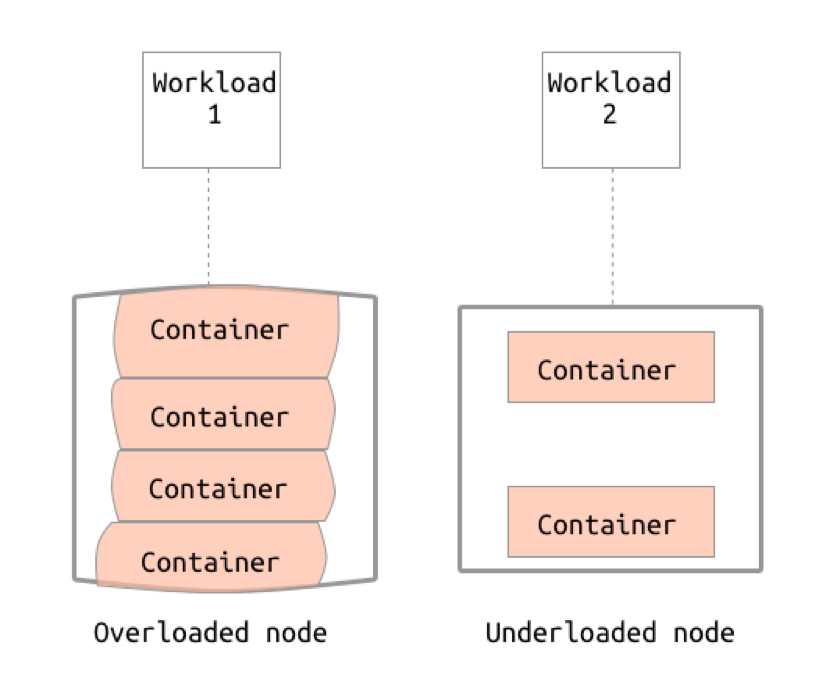
I took four machines, each with 256Gb RAM, 40 CPU cores, 2 SSDs and 4 HDDs, installed LXD and configured a ZFS pool on each node. I’ve then set up a Jenkins job, that would build the project, install it inside the LXD container on one of these machines, export an image and push it to the other three nodes. Each integration test job would then just do lxd clone current-master-snapshot <backend-$i>, run the tests and destroy containers once done. Because of the copy-on-write nature of ZFS, clone operation was now instantaneous. Each node was able to handle about ten test backends until things would start crashing. This was a great result, much better than what VMware was giving us, but with a major drawback: it wasn’t flexible nor scalable. Each test job would need to know exactly on which of LXD nodes to create its backends and, if it required more than 10 of them, they just wouldn’t fit. In other words, without the orchestration system, it was not scalable. With LXD, at that time, we had only two options: use OpenStack or write our own scheduler (which we didn’t want to write).
OpenStack supports LXD as a compute backend, but in 2016 it was all very fresh, barely documented and barely working. I’ve spent about a week trying to configure an OpenStack cluster and then gave up. Luckily, we had another unexplored path: Docker and Kubernetes.
Docker & Kubernetes
After the first pass over documentation, it was clear that neither Docker nor Kubernetes philosophy fit our use case. Docker explicitly said that “Containers are not VMs”, and Kubernetes was designed for running one (or few) application, consisted of many small containerized services, rather than many fat single-container apps. On the other hand, we felt that the movement behind Kubernetes was powerful. It’s a top-tier open-source product with an active community, and it can (should) eventually replace our own, home-grown, orchestration system in the product. So, all the knowledge that we acquire while fitting Kubernetes for the dev infrastructure needs we can reuse later when migrating the main product to Kubernetes. With that in mind, we dove into building the new infrastructure.
We couldn’t get rid of the Systemd dependency in our product, so we’ve ended up packaging everything into a CentOS 7 based container with the Systemd as a top-level process. Here’s the base image Dockerfile that worked for us. We’ve made a very heavy Docker image (20Gb initially, 5 after some optimizations), which encapsulates Orion (ThoughtSpots own container engine), which then runs 20+ of ThoughtSpot services in cgroup containers, and that all roughly corresponds to a single node production setup. It was cumbersome, but it was the quickest way from nothing to something usable.
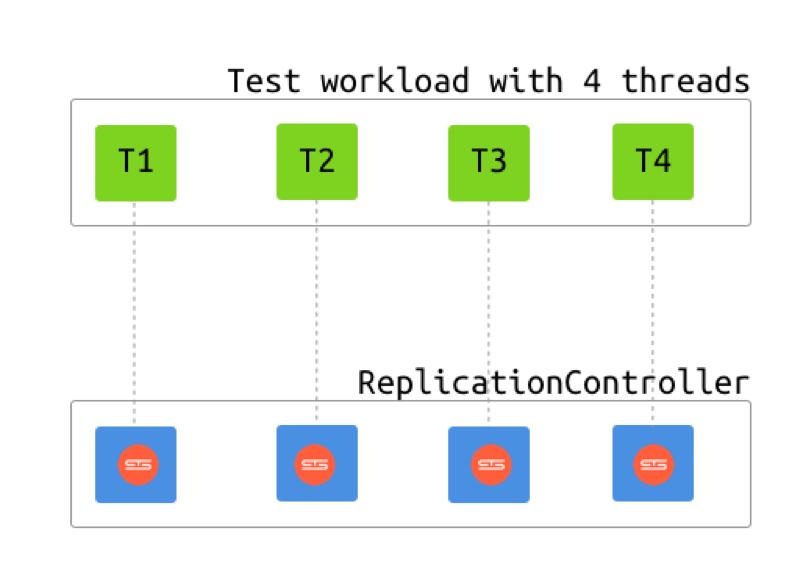
After that, I took a few other physical machines and created our first Kubernetes cluster on them. Among all of the Kubernetes abstractions, only Pod was relevant to our problem, as it’s really just a container running somewhere. For most of our test cases, we would need to create multiple Podsand having the ability to group them by workload would be helpful. Perhaps labels are better suited for this purpose, but we’ve decided to exploit a ReplicationController. ReplicationController is an abstraction that would create a number of Pods (according to a Replication Factor), make sure they are always alive and, on the other end, receive traffic from a Service and redistribute it across the Pods. ReplicationController assumes that every Pod is equal and stateless so that every new Service connection can be routed to a random Pod. In our case, we did not create a Service and just used ReplicationController as a way to group Pods and make sure they get automatically re-created if anything dies. Every test job would then create a ReplicationController for itself and just use the underlying Pods directly.
Pod networking hack
We rely on Pods behaving as real VMs API-wise. In particular, we needed SSH access to every Pod and an ability to talk to dynamically allocated ports. Also, every Pod was obviously stateful, as the image encapsulated the state store in it. This effectively meant that instead of using Services and load balancing through kube-proxy, we had to break into the pod-network directly. We’ve done that by enabling ip forwarding on the Kubernetes master node (turning it into a router) and re-configuring all office routers to route 172.18.128.0/16(our pod-network) through the Kubernetes master node. This is a terrible hack which should never be done in production environments, but it allowed us to quick-start the dev infrastructure, solve the immediate problem and start looking into ways how to make our product Kubernetes-ready in the future.
Fast forward almost two years and here’s how ThoughtSpot’s dev infrastructure looks right now:
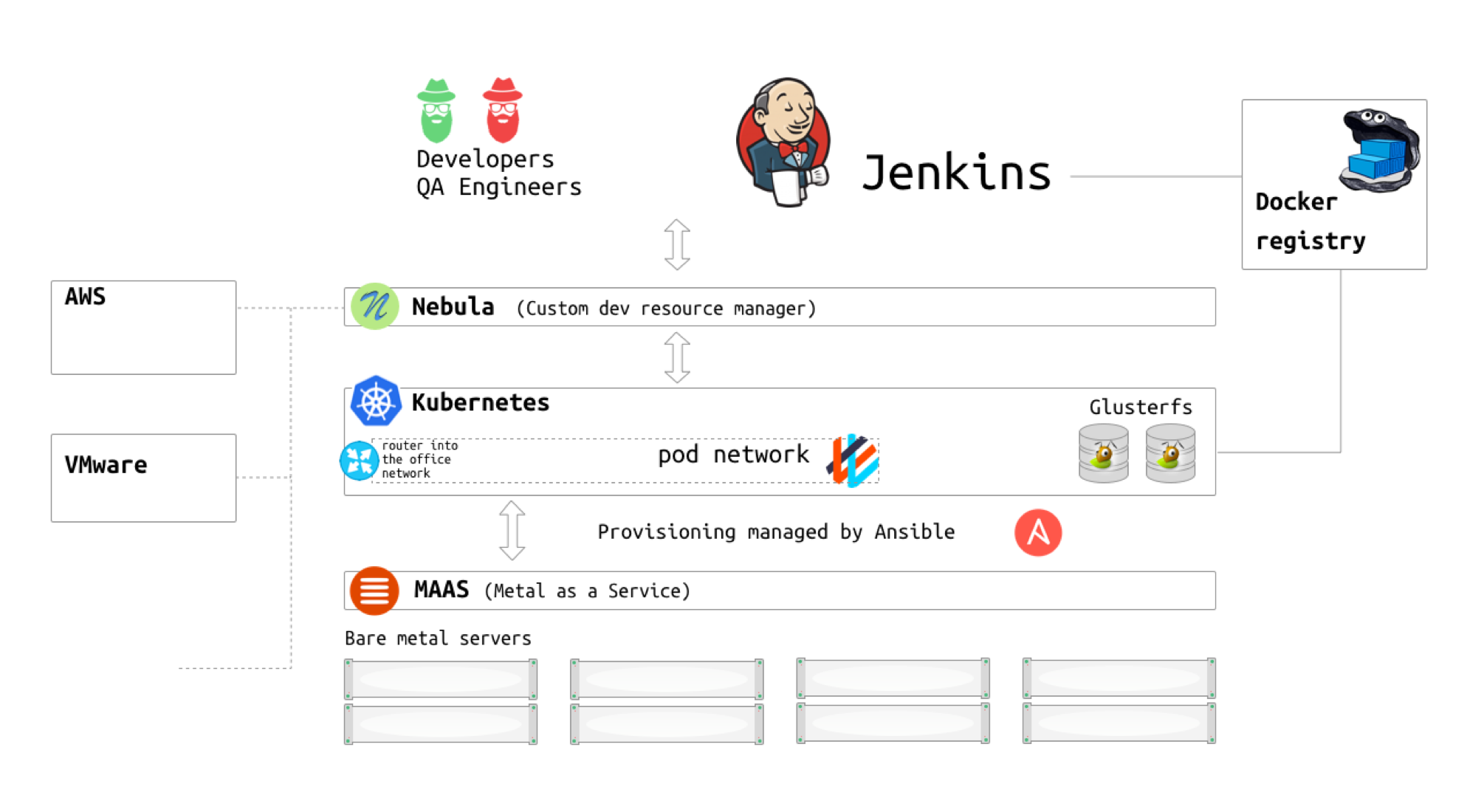
Kubernetes cluster is running on 20 physical machines, providing 7 Tb of RAM and 928 CPU cores combined.
Every host node is running CentOS 7 with 4.4-lt Linux kernel.
We use Weave as an overlay network, and the routing hack is still in place.
We run an in-house Docker registry, to which CI pipeline uploads a product image every time the master or release branch build succeeds.
We use Jenkins Kubernetes plugin to provision Jenkins slaves on Kubernetes dynamically.
We’ve recently deployed Glusterfs on a few nodes and started experimenting with persistent stateful services. This and this were the essential tutorials.
MAAS
During this project, we’ve discovered another great open-source tool, which helped us a lot with managing physical hardware. It’s called MAAS and translates as “Metal as a Service.”<br>It’s a tool, which leverages PXE booting and remote node control to allow dynamic node re-imaging with an arbitrary OS image. On the user side, it provides a REST API and a nice UI, so that you can provision physical machines in AWS style, without actually touching the hardware. It requires some effort to set it up initially, but after it’s there, the whole physical infrastructure becomes almost as flexible as the cloud.<br>Right now we provision plain CentOS 7 nodes through MAAS and then run an Ansible script, which upgrades the kernel, installs all the additional software and adds the node to a Kubernetes cluster. (link to a gist)
Nebula
Most of the developers or CI jobs do not interact with MAAS or Kubernetes directly. We have another custom layer on top of that, which aggregates all available resources together and provides a single API and UI for allocating them. It’s called Nebula, and it can create and destroy test backends on Kubernetes, as well as on the old VMware infrastructure, AWS, or physical hardware (through MAAS). It also implements the concept of a lease: every resource provisioned is assigned to a person or a CI job for a certain time. When the lease expires, the resource is automatically reclaimed or cleaned up.
LXCFS
By default, Docker mounts /proc/ filesystem from the host and hence /proc/stat (meminfo, cpuinfo, etc) do not reflect container-specific information. Especially, they do not reflect any resource quotas set on cgroup. Some processes in our product and CI pipeline check for the total RAM available and allocate its own memory accordingly. If the process doesn’t check the limit from cgroup, it could easily allocate more memory than allowed by a container quota, and then get killed by the OOM killer. In particular, this was happening with a lot the JS uglifier, which we were running as part of the product build. The problem is described and discussed here, and one of the solutions for it is to use LXCFS.
LXCFS is a small FUSE filesystem written with the intention of making Linux containers feel more like a virtual machine. It started as a side-project of LXC but is useable by any runtime.
LXCFS will take care that the information provided by crucial files in procfs such as:
/proc/cpuinfo<br>/proc/diskstats<br>/proc/meminfo<br>/proc/stat<br>/proc/swaps<br>/proc/uptime<br>are container aware such that the values displayed (e.g. in /proc/uptime) really reflect how long the container is running and not how long the host is running.
Conclusion
It took us quite a lot of time to figure all the things out. There was a tremendous lack of documentation and community knowledge at the beginning when we were just starting with Kubernetes 1.4. We were scraping the particles of information from all over the web and learning by debugging. We’ve also made dozens of changes to our product, re-designed the CI pipeline and tried many other things which are not mentioned in the article. In the end, however, it all played out well, and Kubernetes became a cornerstone of dev infrastructure in ThoughtSpot, providing much needed flexibility and allowing to utilize all the existing hardware, available in the office. I left the company in September, but the project got handed over to other developers and keeps evolving. I know that many people are trying to build something similar for their companies, so I would be happy to answer any questions in the comments below.
Originally published in HackerNoon



