

Ubuntu has been a backbone of enterprise technology for years. However, with Ubuntu 12.04 getting end-of-life in April 2017 and limited support from Ubuntu community for things like kernel bugs and security patches, it no longer made sense for us to continue running Ubuntu 12.04 appliances in the field. That meant we needed to migrate our Ubuntu clusters to CentOS. We’ve dubbed this workflow as 'os reinstall' since we actually reinstall the OS on our machines in the field.
In this article we’ll break down how Thoughtspot approached cluster OS reinstall while ensuring fault tolerance, failure isolation, and the ability to resume from a checkpoint on failure.
Orchestrating the Reinstall Workflow with Orion
We use Orion, the ThoughtSpot cluster manager, to orchestrate this workflow.
After receiving an os reinstall request from Thoughtspot's command line interface, which we call tscli, the Orion master performs a series of steps with the end goal of transforming an Ubuntu Cluster into a CentOS cluster. Orion master also records progress in Zookeeper at the end of each step to ensure that the Recovery Point Objective (RPO) from any faults in Orion master is no more than a single step. This ensures that the Recovery Time Objective (RTO) is also minimal, and takes no more time to complete than any single step. The choice to use Zookeeper was simple, given we already use it for a variety of other purposes, like leader election, configuration management, and others forms of coordination or synchronization between multiple instances of a distributed service.
The first step in the os reinstall workflow is running preflight checks. This ensures two things: first, we don’t move ahead in the workflow while having known failures in the system; second, it prevents us from deleting files or directories that might be of value to the end users. If the preflight checks fail, they cause Orion master to stop running the workflow. User intervention is then required to fix the cause of failure and then resume the workflow.
Preparing for the Reinstall
Once all the preflight checks have been successfully conducted, the Orion master starts the reinstall OS on the cluster in a rolling fashion, one node at a time. Before starting the reinstall on a node, the Orion master marks the node as a “canary” to prevent background threads, such as the scheduler thread and the health-checker thread, from assigning any tasks to this node, or from taking corrective actions if the node is found to be “unhealthy”. The Orion master then creates a system service (upstart service) on the node to perform the reinstall.
Writing an upstart service (named install-centos in our case) gives fault tolerance against random system and process failures, since the Upstart daemon is instructed to always restart the service in case of failures. The system service follows the same philosophy to minimize RPO and RTO, checkpointing after running each step of reinstall. The only difference now, is that there is no need to checkpoint progress to Zookeeper, since the workflow of `install-centos` is confined just to that one node. The steps for reinstall on a node are predefined by the user in a serialized protobuf file, which serves both as input to the install-centos service, as well as the place for checkpointing status of each step during the reinstall. By checkpointing these steps, we can also monitor the progress of the install-centos service at every step of the way.
Making the Conversion
The steps defined in the proto file are nothing more than a logical sequence of steps which, when performed to completion, convert an Ubuntu node into a Centos node, preserving networking and other system configurations of the machine.
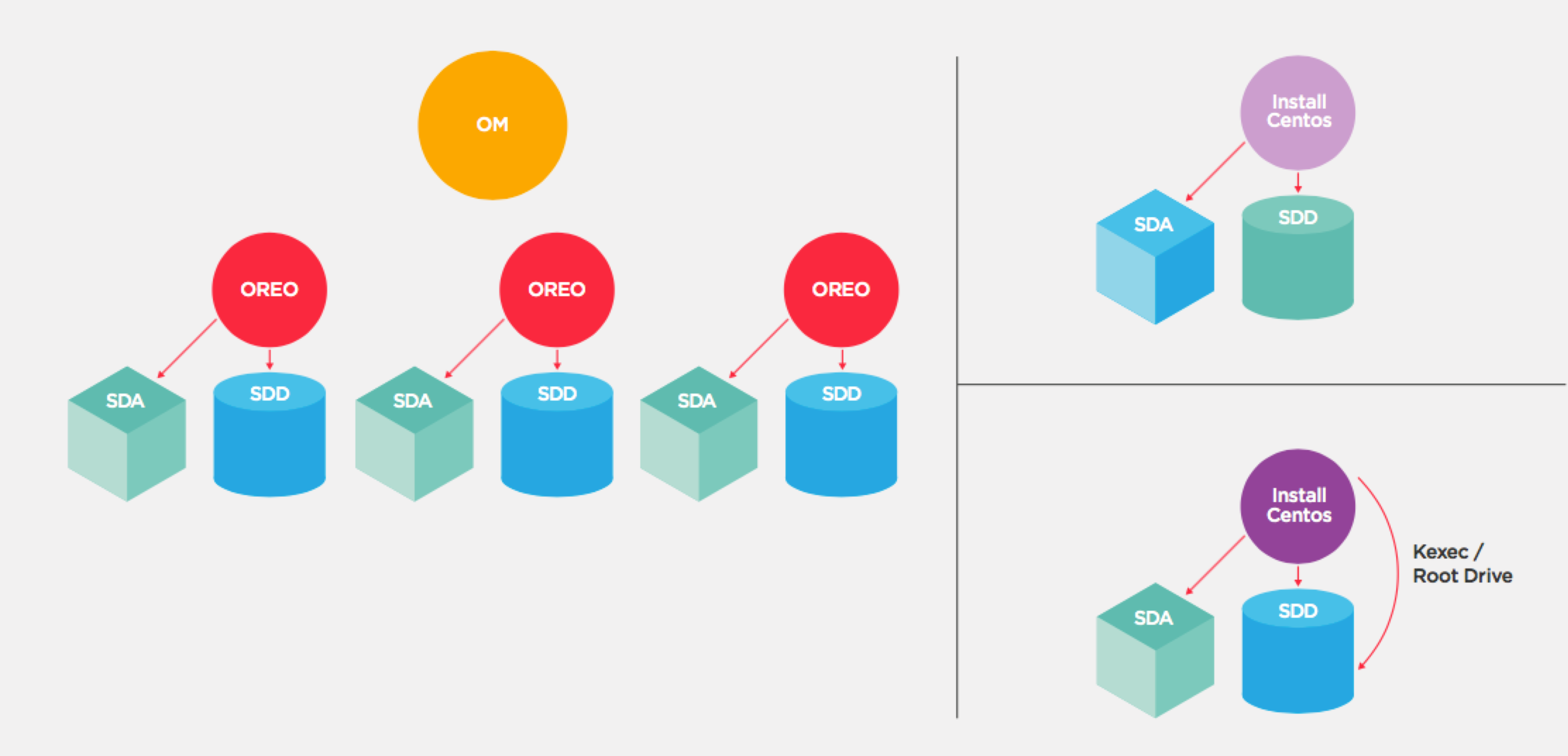
Broadly speaking, the steps are as follows.
Prepare to boot with secondary disk as the root drive
Boot from secondary hard drive using `kexec`
Image the primary drive (SSD)
Boot from the primary drive
In order to preserve the network configuration across the entire distribution, we use our site-survey tool, node-scout, to checkpoint the configurations and then restore the configurations directly from the checkpoint.
Conclusion
Putting everything together makes this an amazing workflow for the cluster reinstall OS. Though this workflow was written to be performed just once in a cluster's lifetime, the same principles and design patterns can be reused to solve similar complex problems. In fact, a lot of design principles were borrowed from the distributed cluster updates overhaul.
Up Next: Taking it to Larger Clusters
The overall latency of the cluster reinstall operation is typically a couple of hours for a 3-4 nodes cluster since the 'install-centos' performs an extensive set of operations. Doing it on larger clusters will increase the overall time linearly which is not feasible because it implies so many hours of cluster downtime. So instead of reinstalling one node at a time, we’re looking into ways to work on multiple nodes in parallel.
This iseasier said than done. There are real challenges to parallelizing. We won't want to reinstall on the nodes which are necessary for the availability of the entire cluster like nodes running Zookeeper, HDFS namenode, journalnode, etc. Moreover, we need to ensure that we never bring down the set of nodes together leading to a state where we have no replica for any Block.
We’ll have to be careful, but there is room for additional optimization. Luckily enough, we won’t have to rework anything like reinstall OS, because CentOS brings the power to perform distribution upgrades. We’ll cover how in future blogs - subscribe to our blogs to make sure you don’t miss it!



