

And what you can do about it
Most teams deploying AI agents on their data are watching the wrong things. They check whether the query ran and whether the number looks plausible. When both checks pass, the agent gets credit for a correct answer, and the output flows into dashboards, decisions, and the next agent in the chain.
There's a gap between those two checks and actual correctness, and it's where the expensive mistakes live. Getting to a correct answer requires more than a formally valid calculation. It requires the business context around the number: what the column actually represents, which definitions and rules apply, and whether the data being queried is the data the business considers authoritative for the question being asked.
The invisible mistake
Consider a question a Monday-morning VP might produce: How many active users did we have last quarter in the Northeast? An AI agent inspects the warehouse, locates a column called active_users_v2, writes a clean query, and returns 847,000.
Every surface signal says this went well. The SQL executed, the number is plausible, the agent cited its source, and a governance tool logged the access. Nothing in the output invites a second look.
Now the part nobody sees. The column active_users_v2 was created after a product launch two years ago, and it still reflects the activity threshold the growth team used then, not the one they use now. The join silently excludes trial accounts using logic that made sense in 2023 but doesn't after the free-tier redesign. The "active" definition itself reflects a decision the product team made in a Slack thread and never encoded in the schema.
The agent hasn't invented anything; it has interpreted a raw column without the rules that give the column meaning, and because the infrastructure around the query is governed, the output inherits the appearance of being governed too.
When an agent gets a number wrong in a world with agents, that number propagates at machine speed into dashboards, decisions, and the input of the next agent, with no slow human follow-up question to catch it.
What the "right query" actually requires
The phrase "the agent ran a query" makes a complicated process sound simple. A right query depends on several things being true before the SQL ever runs.
First, the agent has to find the right asset. Warehouses accumulate stale tables, deprecated views, and columns nobody owns; an agent with no signal about which assets are production-grade will grab whatever is syntactically closest to the question. Atlan's Enterprise Context Layer does this work, telling agents which assets have been certified, who owns them, how they're lineage-connected, and who has authority to act on them.
Second, the asset has to be queried in a governed way, with security and access entitlements enforced at query time. A query that returns the right value but exposes data the user was never supposed to see isn't a correct answer; it's a compliance incident with a numeric payload.
Third, the agent has to translate the business question into the right computation. This is where active_users_v2 lives. Certification told the agent the column was production-grade; lineage told the agent where it came from. Neither signal told the agent that "active user" in this company, in this fiscal period, requires joining user records to session data, excluding trial accounts, and applying the activity threshold the growth team agreed on last quarter.
That third piece is what a semantic layer is for: the place where the business says, in machine-readable form, what it means by an active user, how it defines churn, and which rules apply before a number becomes an answer. The two layers – Atlan’s Enterprise Context Layer and ThoughtSpot’s Semantic Layer – make each other stronger in production:

Context tells the agent which data is trustworthy and why. The semantic layer tells the agent what that data means: the business definitions, fiscal rules, and calculation logic that turn a column into an answer. Enterprises deploying agents need both because the gap between a clean query and a correct answer has two halves, and each layer closes one of them.
Why the semantic layer is harder than it looks
Agents made this problem urgent, and every BI vendor in the category is now racing to ship a semantic layer in response. What most of those efforts are discovering is that building one well takes years, not quarters. Luckily, ThoughtSpot has been focusing on this since day one.
A production-grade semantic layer has to capture business definitions in a way humans can actually verify, not just infer from raw schema, so the agent is reasoning over tribal knowledge that the business stands behind. It has to be stored in a format agents can directly ingest, with the metadata and context they need to resolve a question's intent.
It has to compile those definitions into deterministic SQL, with row-level and column-level security applied to every query, so governance travels with the query instead of being bolted on after. And it has to stay maintained as a living artifact, because a semantic model frozen at deployment will be wrong within a quarter.
None of those requirements is impossible on its own. Getting all of them right, at enterprise scale, in a system that agents can query reliably, is the kind of engineering problem that takes a decade to solve.
That's why Spotter Semantics holds up under the load agents are placing on it now, and why the BI tools first confronting this problem in 2025 are going to spend the next several years catching up to where the category needs to be.
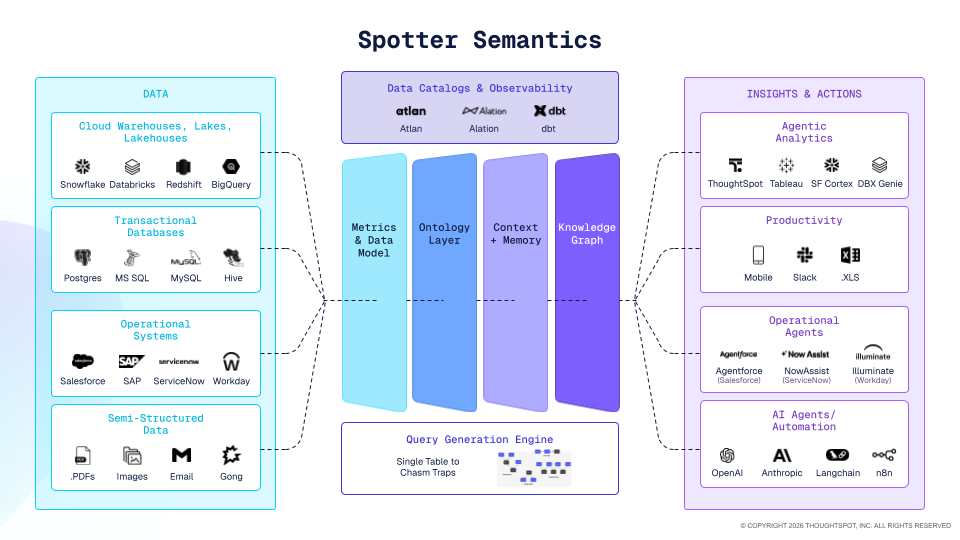
ThoughtSpot focused on this foundation when building the platform, while most other vendors in the space today are trying to bolt it on top.
What we believe
The semantic layer has quietly become one of the most consequential pieces of infrastructure an enterprise can own in the agent era. It's the boundary between an AI system that behaves like a trustworthy colleague and an AI system that produces confident, governed-looking answers that happen to be wrong at scale.
Atlan’s Enterprise Context Layer ensures Atlan agents reach for trustworthy data in the first place. The semantic layer makes sure that once the agent has the right data, it interprets the data the way the business actually means it. When both are in place, an agent can take a business question, pull data that's been certified and governed, apply definitions the business has agreed on, and return an answer a finance team would stand behind. That's the version of enterprise AI worth deploying, and it's the version the next wave of agent-driven work will be built on.
Make sure your AI agents are reaching for trusted data and returning answers your business can act on. See how ThoughtSpot and Atlan can help.



