





先日Samsungの従業員が機密情報を流出させていたことが発覚。さらに、イタリアがChatGPTを全面的に禁止するなど、GPTにまつわる熱狂が現実味を帯びてきました。AIの第一人者であるHinton氏が先週Googleを退職し、バイデン大統領はAIリーダーとワシントンで会合を実施、生成AIによるビジネスモデルへの脅威から複数の銘柄が急落するなど、誇大広告と懸念が加速しています。私は、このような停滞は破壊的技術につきものの生みの苦しみであり、GPTがデータ・分析分野を大きく向上させる過程であると楽観的な見方を続けています。
先行者利益と創造力の重要性
30年以上にわたりデータ・アナリティクス業界に携わってきた中で、業界における主な破壊的イノベーションを振り返ってみると、その多くが漸進的なものでした。そのため、ベンダーも顧客も静観するアプローチを取るのが常でした。<br>IT業界には、「ドットゼロのリリースは絶対に採用しない」という考え方があります。結局はソフトウェアが要であり、ソフトウェアにはバグがつきものだからです。一方で、インターネットとクラウドという、業界で巻き起こった2つの変化を思い出してみましょう。
1999年、MBAを取得するためDowのグローバルBIリーダーを辞めたばかりの時のことです。私は、ソフトウェア配布の簡素化や導入増という点で、インターネットがBI業界をどう変えるかについて独自の研究プロジェクトを実施しました。ご存じのように、今やフロッピーディスクはコレクターズアイテムとなり、インターネットはデジタル経済の基礎となっています。<br>その年のマーケティングの最終試験は、イエローページがインターネット戦略をとるべきかどうかというものでした。私は論文で「インターネット戦略をとるべき。先行者利益が重要」と結論づけました。教授がこの論文にC評価をつけたので、低評価の理由について説明を求めたところ、「ダイヤルアップは遅すぎるし、インターネットが主流になることはない」と断言されました。今となっては笑い話ですが、技術の現状しか見えない人もいるのです。教授にはネットワークや技術的な素養がなかったため、ブラウザーや高速インターネットの進歩の速さを理解できなかったのでしょう。
最近では、2012年からクラウドデータプラットフォームが普及し始めた一方で、2020年になってもなおクラウド移行を拒む顧客が一部存在しました。その多くは、セキュリティーやコントロールの消失への誤解からくる懸念や、典型的な「NIH症候群」(Not Invented Here症候群、自前主義)が原因でした。今回のパンデミックをきっかけとして、多くの組織がクラウドへの移行を加速させました。すでにデジタルトランスフォーメーションとクラウド化への道のりを歩みだしていた組織は、出遅れた組織に比べて2倍から3倍の成長を見せ、81%の利益改善(見込み)を実現しました。
あるCOOが、データ・アナリティクス業界について「人材不足というより、創造力が足りない」と述べたことがあります。私はこの評価と同じ意見です。今まさに、生成AIを活用して、データ・分析の漸進的というよりはむしろ革新的な改善を実現する方法について創造力を働かせるべき時なのです。私たちは今、生成AIにおいて、先行者が後発者に対して圧倒的かつ持続的な競争優位性を確立する決定的瞬間にいます。知識やガードレールなしに無謀な行動をとる先行者は痛い目にあうでしょう。AIの倫理と説明可能性を重視しながら生成AIを採用したものが、勝者となるのです。ここからは、GPTなどの生成AIがデータ・アナリティクス業界を変革する4つの方法をご紹介します。
GPTがデータ・分析ワークフロー全体を変革。
1.データの収集と運用プロセス
デジタル取引によって消費者はよりインテリジェントにオンラインショッピングができるようになり、検索インターフェイスは顧客と商品のマッチングに役立っています。一方で、多忙な作業者の負担を軽減するスマートなエージェントとして、AIアシスタントが支持を得つつあります。歴史的に、チャットボットの多くはルールに基づいていました。そのため、医師に電話をかけたりウェブサイトにアクセスしたりすると、ボットは、予約や処方薬の補充に限定された厳格なプロンプトプロセスに従うでしょう。生成AIを使えば、このボットは、初歩的な医療に関する質問や在宅医療に対応できるようになります。人間による関与は不可欠ですが、看護師から回答を得るスピードが大幅に向上します。看護師が対面診療を勧める場合、すべての情報と症状を電子カルテに容易に入力することができます。
最終的には、内部データと外部データがよりシームレスにマージされ、半構造化データと合成データにわたって活用されると予測しています。たとえば、小売業のビジネスユーザーが「Cindiはどの程度の確率で自社の最新商品を購入するか」と質問すると、Cindiに似たアバター写真と、過去に購入された自社商品の画像や詳細、さらに外部の人口統計データ、クレジットカードパターン、傾向スコアが表示されます。
2.データモデリングとメタデータ
データメッシュの台頭により、データ製品の所有権は事業部門に移りつつあります。より高度な分野の専門知識とローコード製品が、このような移行を可能にしています。一方で、データへの接続、分析のためのクレンジング、変換を行うには、高度な技術的スキルが現状求められます。GPTやその他のLLMで合理的なコードを生成し、このようなタスクに活用することで、よりスマートなローコードエクスペリエンスが実現します。
特にビジネスメタデータの処理は、負担が大きく手間のかかる作業です。データカタログはビジネス用語の共通認識を図るうえで重要です。しかし、Eckerson Groupの調査によると、そのようなメタデータを記述したりフィールドに入力したりしなければならないことが、データカタログの導入率が低い理由の1つとなっています。類義語を生成し、算出方法を説明するGPTの機能によって大きな改善が期待できると考えています。
たとえばThoughtSpot Sageでは、GPTによってデータモデルの類義語が生成されます。クラウドネイティブのモダンデータカタログであるAtlanは先日、Atlan Co-Pilotを発表しました(6月中旬にリリース予定)。
データモデルや分析ツールで指標を計算するには、各プラットフォームに固有の正確な構文を学ぶ必要があります。括弧が正しい位置にあることを確認する必要があるうえ、プラットフォームで使うのが一重引用符なのか二重引用符なのかも各ツールによって異なります。
たとえば、IF-THEN-ELSEを使って特定の商品をグループ化する関数を作成したい場合、ThoughtSpotでは次のように値を一重引用符で囲みます。

LookMLを使うと、以下のようなコードになります。

Excelで同様の関数を作成する場合は、各値に二重引用符を使用し、構文も若干異なります。一連のSQLやdbtなどの指標レイヤーでは、CASE文を使用することで同様の出力が可能です。この点でGPTは、優れたアクセラレーターとなります。
3.インサイトの民主化
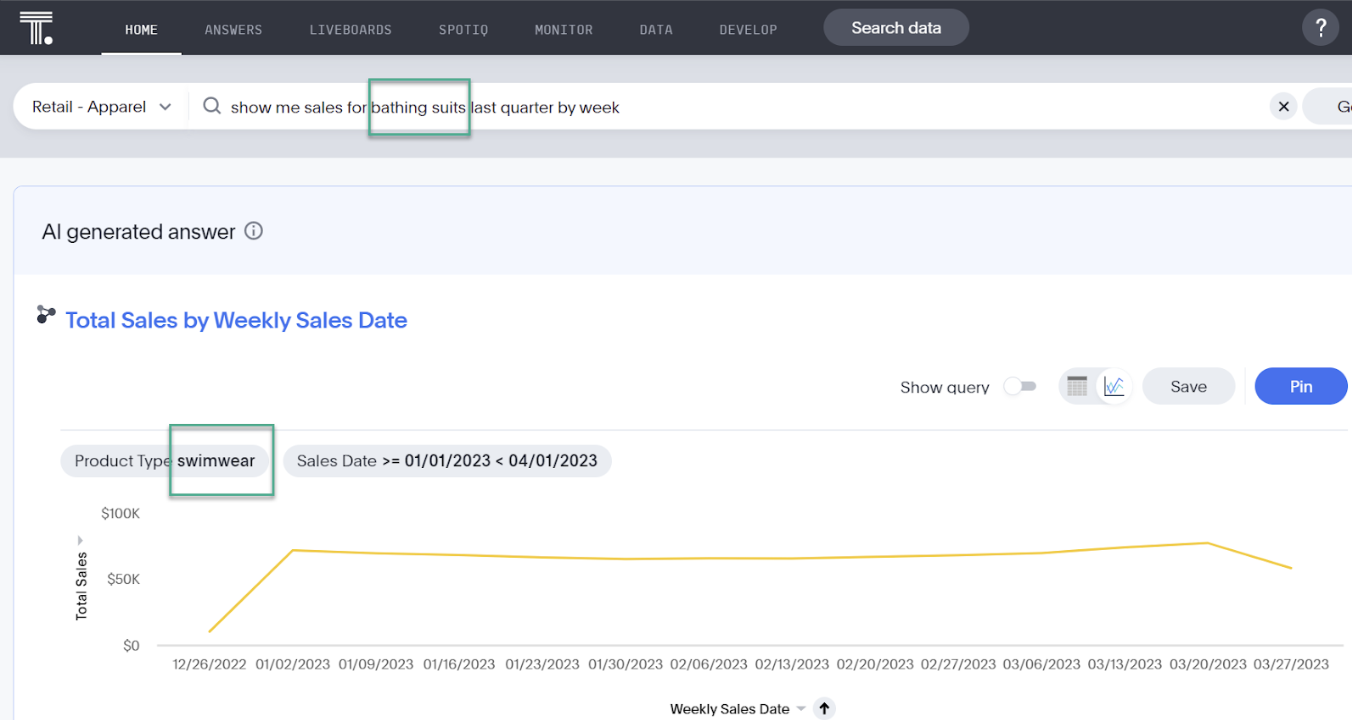
2007年、私は著書の中で、検索を活用することにより誰もがデータにアクセスできるようになると述べました。このビジョンは、業界で目の当たりにしたニーズと、さまざまなスタートアップのイノベーションに基づいています。ThoughtSpotが初の製品をリリースするまでには、さらに7年の歳月が必要でした。この3年間で、ライブクエリーによるクラウドデータプラットフォームへのアクセスにシフトし、モダンアナリティクスクラウドをリリースしたことで、データと配布の幅が広がりました。検索は、専門家向けに設計されたビジュアルディスカバリーツールに比べて使いやすいインターフェイスではありますが、構文をある程度学習する必要があります。たとえばビジネスユーザーは、「Weekly Sales Swimwear Last Quarter」(週間売上 水着 前四半期)という検索語句を入力できます。検索語句にはインデックス付けされたデータ(「swimwear」(水着))を用いる要素もあれば、自然言語をシミュレートするためにThoughtSpotのインテリジェンスを用いる要素(「weekly」(週間)と「last quarter」(前四半期))もあります。
GPTの自然言語処理と生成AIの能力をThoughtSpotの特許取得済み検索技術と統合したThoughtSpot Sageでは、「Show sales for bathing suits last quarter by week」(水泳着の前四半期の売上を週ごとに表示して)というようなかたちで質問をより自然に投げかけることができます。GPTは、「bathing suits」(水泳着)というテキストを自動的に「swimwear」(水着)に変換し、「show me」(表示して)は無視します。また、「show me revenues」(収益を見せて)と言った場合、ThoughtSpot Sageは、GPTが理解しているように収益と売上が類義語であることを理解します。従来であれば、モデラーが収益を売上フィールドの類義語として明示的に定義しなければならなかったでしょう。
生成されたSQL:

GPTにより検索の使いやすさが向上します。さらに、AI提案による3つの質問から始めるといったような、検索方法の候補を提案するThoughtSpot Sageの機能によってデータがより身近なものになります。
4.データリテラシー
2023年のトレンドに関する電子書籍に記載されているように、データリテラシーとデータフルエンシーの向上は、今やデータに精通したCEOの目標となっています。一方で、多くの人はテクニカルリテラシーとデータリテラシーを混同しています。データリテラシーの基礎は、主要なビジネス用語や分析的概念を理解することです。LLMは、公開データソースのトレーニングから、企業独自のデータソースのトレーニングに移行していくと予想されます。Bloombergはいち早く金融データをトレーニングした独自のLLMを発表し、TruvetaやJohn Snow Labsはヘルスケアデータをトレーニングしています。これにより、共通言語を促し、新入社員の研修やスキルアップを加速させるうえでAIが非常に大きな影響力を持つことになるでしょう。最近行われたDataCampの調査によると、正式なデータリテラシープログラムを策定するための具体的な予算がない組織は40%に上りますが、そのようなプログラムを実施した組織では意思決定や顧客サービスの向上が見られます。これにAIを応用することで、アプリ内・コンテキスト内トレーニングを経済的に実施できます。
さらに、自身のデータリテラシーのスキルに自信があると感じているビジネスパーソンはわずか21%。54%の組織がデータリテラシーにスキルギャップがあると答えています。恥をかきたい人はいません。近づきがたく多忙なデータ専門家ではなくAIボットに質問できるようになれば、このような摩擦を減らすことができるでしょう。一例として、私は最近、Character.ai(ベータ版)を使ってData Sherpaというボットを作りました。中央値と平均値についてData Sherpaが答えた内容は以下のとおりです。

ドメイン特化型LLMでは、このようなボットがデータフルエンシーを向上させる理想的な手段となるでしょう。ユーザーは、「OTIFは何の略?」(On Time In Full)あるいは「当社が定義する顧客とは?」(無料会員を含むのか、それとも有料会員のみなのか)といった質問をできるようになります。GPTの最新リリースでは、画像データも扱えるようになったため、複雑なサンキーダイアグラムをアップロードして自然言語テキストを生成することもできるようになりました。
「万一」と「間違いの可能性」
今こそ、「万一」を想像し、データの収集から洞察、行動までの分析ワークフロー全体を見直す時です。また、間違いの可能性を想定し、AI倫理を重視するとともに、あらゆるAIとの対話において人間が関与することを確実にすべき時期でもあります。AI競争を一時停止したいと考える人もいるかもしれませんが、私は今こそ、良いことも悪いことも含めて積極的にシナリオモデルを策定すべき時だと考えています。サイバーセキュリティーの専門家が倫理的ハッカーと連携するように、AIが悪用される可能性を想定し、そのリスクを最小限に抑えるセーフガードを構築するハッカーが必要なのです。当業界における決定的瞬間を改めて思い返してみると、Blockbusterがインターネットをもっと真剣に捉えていたらと思わずにはいられません。また、かつてリレーショナルデータベースで誰もが認めるマーケットリーダーであったOracleが、クラウドデータプラットフォームを追求するSnowflakeやGoogleにマーケットシェアを確実に奪われている状況についても同じことが言えます。
生成AIが業界をどのように変えるかについて詳しくは、Beyond(オンデマンド)をご覧ください。





