





今日のデータ処理に関するイノベーションのスピードは、私達がこれまで考えていた以上に加速しています。Databricksは最近、Databricks SQLの提供を発表しました。これは、対話型分析を大規模に提供することを目的として、Delta Lakeの基盤上に構築された進化版のソリューションです。このソリューションをThoughtSpotのモダンアナリティクスクラウドと組み合わせることにより、社内の誰でもデータレイクにシンプルにアクセスして、独自の質問から答えを得られるようになります。
レイクハウスとは
データレイクハウスの概念が広まってきたのは、ここ数年のことです。これはデータウェアハウスとデータレイクの融合に関連しており、両方のテクノロジーの急速な変化によって引き起こされています。従来のデータウェアハウスはストレージ容量が非常に限られていたため、基本的なビジネスデータの保存にのみ使われていました。その結果、その他の各種データの保存場所としてデータレイクが登場しました。また、その規模の大きさから、データレイクを探索して値を抽出するには高度な特殊スキルやツールが必要でした。データレイクハウスは、以前はデータウェアハウスのみに限られていた分析のタイプを、データレイクの規模で実現するために誕生しました。
しかしながら私達は、データレイクハウスの柔軟性を持ってしても、データレイク上で検索を可能にするには、まずデータを検索用に整理する必要があることがわかりました。データレイクには当然ながら多種多様なデータが大量に含まれますが、検索ベースの分析を行うには、データセットをSQL対応の構造にし、さらにGoogleなどの消費者向けソリューション並みの応答時間になるよう最適化する必要があります。Delta Lakeはそのような構造になっており、高性能なクエリー用に最適化されたACID準拠のストレージレイヤーと、分析可能な集約済みのビジネスレベルデータを格納する「ゴールド」テーブルのキュレート機能が備わっています。また、Databricks SQLを追加することで、対話型クエリーをサポートするために設計された演算レイヤーを提供します。
データレイクハウスを誰でもアクセス可能に
Databricks SQLとThoughtSpotを組み合わせると、企業は社内分析の枠を超えて、自社製品の一部としてデータアプリを提供できるようになります。Databricksは大規模で柔軟性が高い上に従量課金制なので、データアプリ用のデータプラットフォームとして理想的です。また、ThoughtSpot Everywhereの新機能を利用すれば、開発者がデータレイクハウス上で対話型のデータアプリを簡単に構築できます。
データコレクションの内容は企業ごとにそれぞれ異なりますが、社内ユースケース向けでもデータアプリに組み込む場合でも、Databricks上にThoughtSpotを展開して利用し始めるステップは同じです。次に、具体的な方法について説明します。
ステップ1:Delta Lake内のデータを検索用に整理する
検索ベースの分析用に最適化された「ゴールド」テーブルで、データセットが検索ベースの分析用に最適化されていると、ThoughtSpotでの検索が一層効果的になります。ACIDトランザクションとスキーマ展開をサポートしているDelta Lakeは、高品質で信頼性の高いデータを提供し、ThoughtSpotでの検索のパフォーマンスメリットを最大限に高めます。
ステップ2:Databricks環境内でDatabricks SQLエンドポイントを作成する
クエリーの実行に不可欠なのは、必要な時間内にクエリーを実行できるだけの十分な演算能力があることです。同時に、Databricksのような消費ベースのプラットフォームでは、演算能力がコスト要因にもなります。コスト効率を維持すると同時に、必要なクエリーパフォーマンスを実現するには、Databricks SQLエンドポイントを適切なサイズにすることが重要です。ThoughtSpotでは、Photonを有効にすることも強くお勧めしています。これはDatabricksのApache Spark対応のベクトル化クエリーエンジンであり、最新のCPUアーキテクチャーを活用して超高速なデータ並列処理を実現し、高度なクエリー処理を実行できるよう設計されています。
ステップ3:ThoughSpotをエンドポイントに接続する
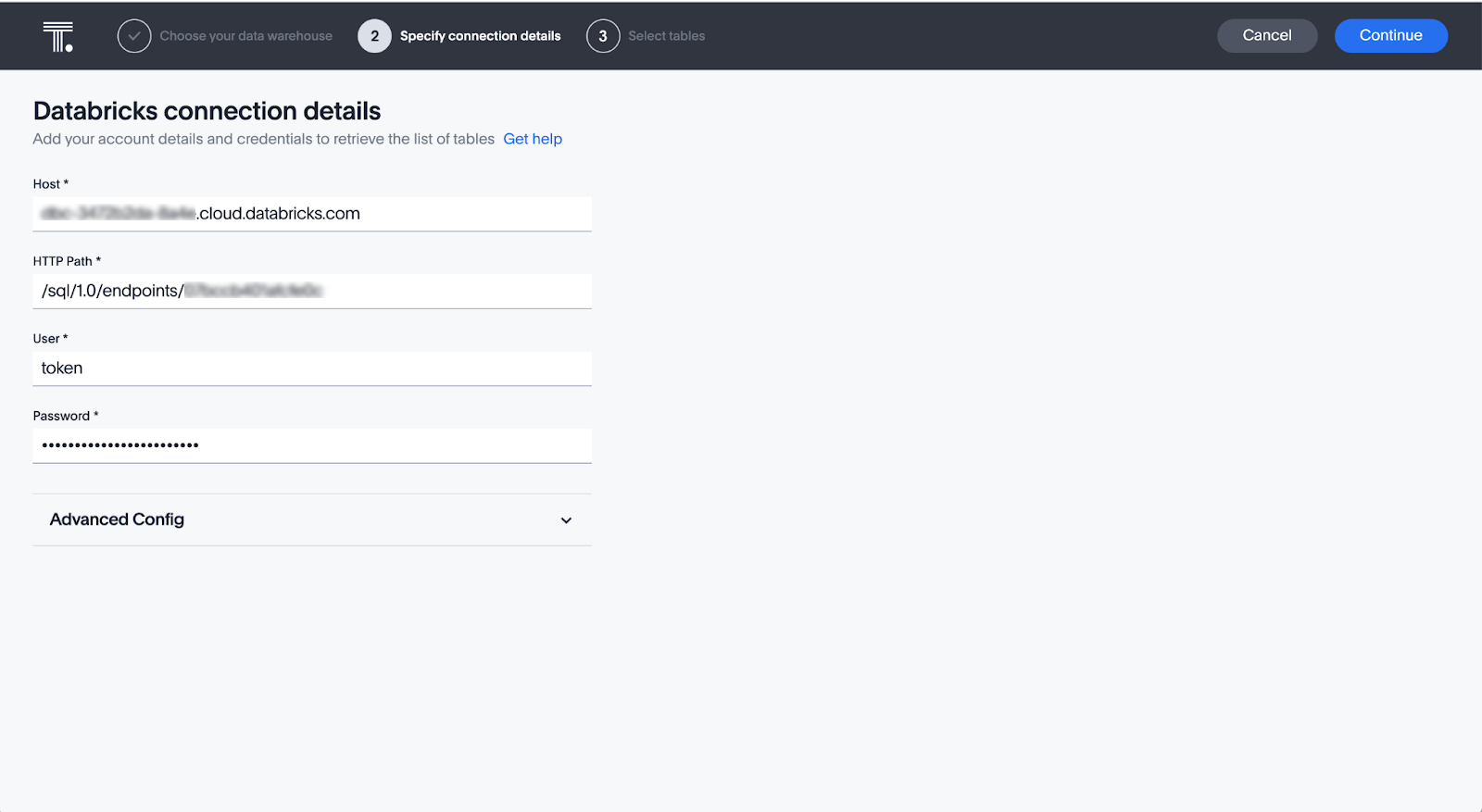
ユーザーは「ThoughtSpot Connections」ページで、Databricksを含む先進のクラウドデータプラットフォームへの接続を作成できます。Databricksインスタンスの詳細(ホスト名とHTTPパス)とログイン認証情報を入力すると、ThoughtSpot接続が作成されます。ユーザー名とパスワード、またはパーソナルアクセストークンを使用すると、セキュリティーが向上します。パーソナルアクセ/ストークンを使用する場合は、ユーザー名としてトークンを入力します。
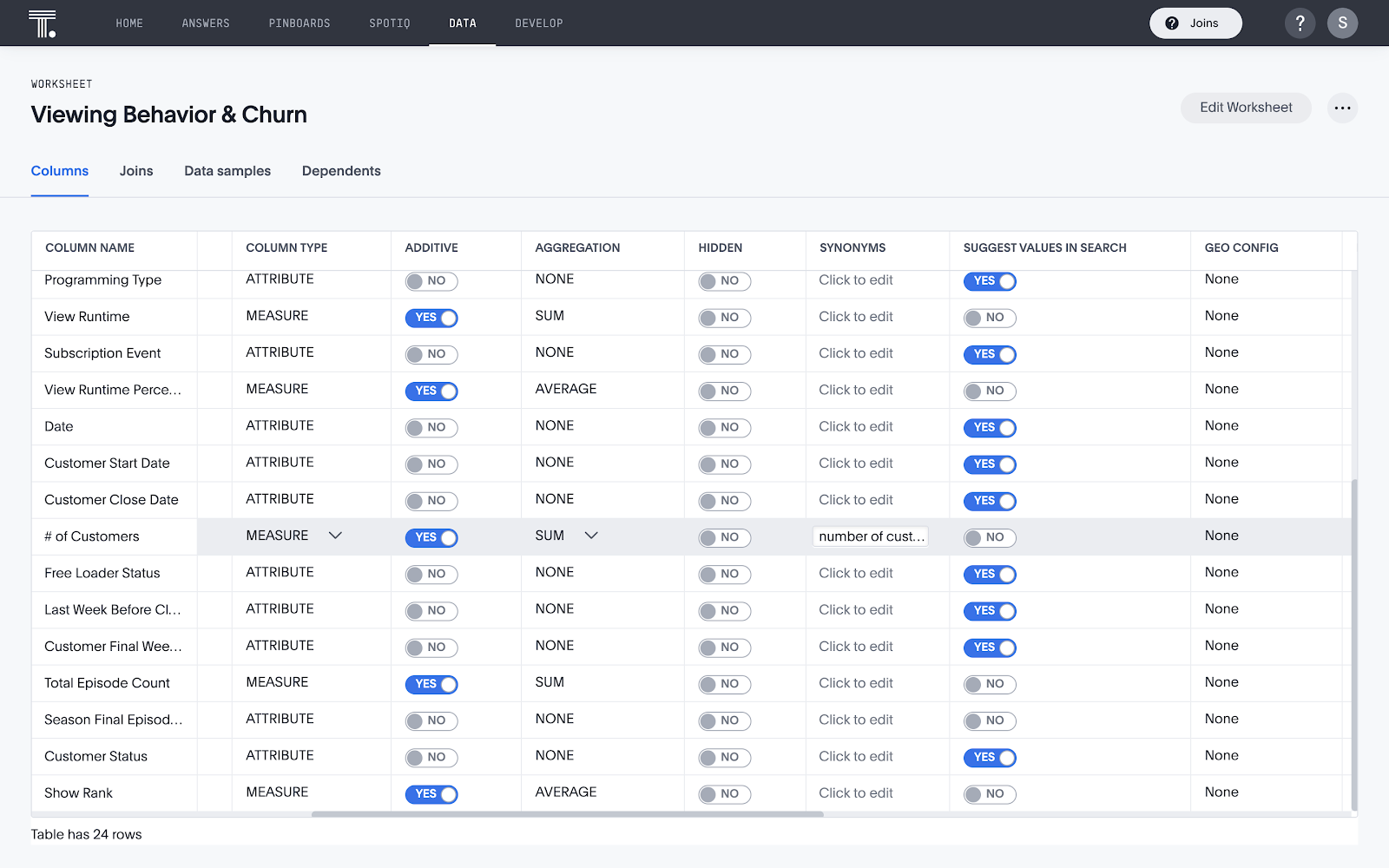
<br>ステップ4:検索可能にするテーブルを選択する
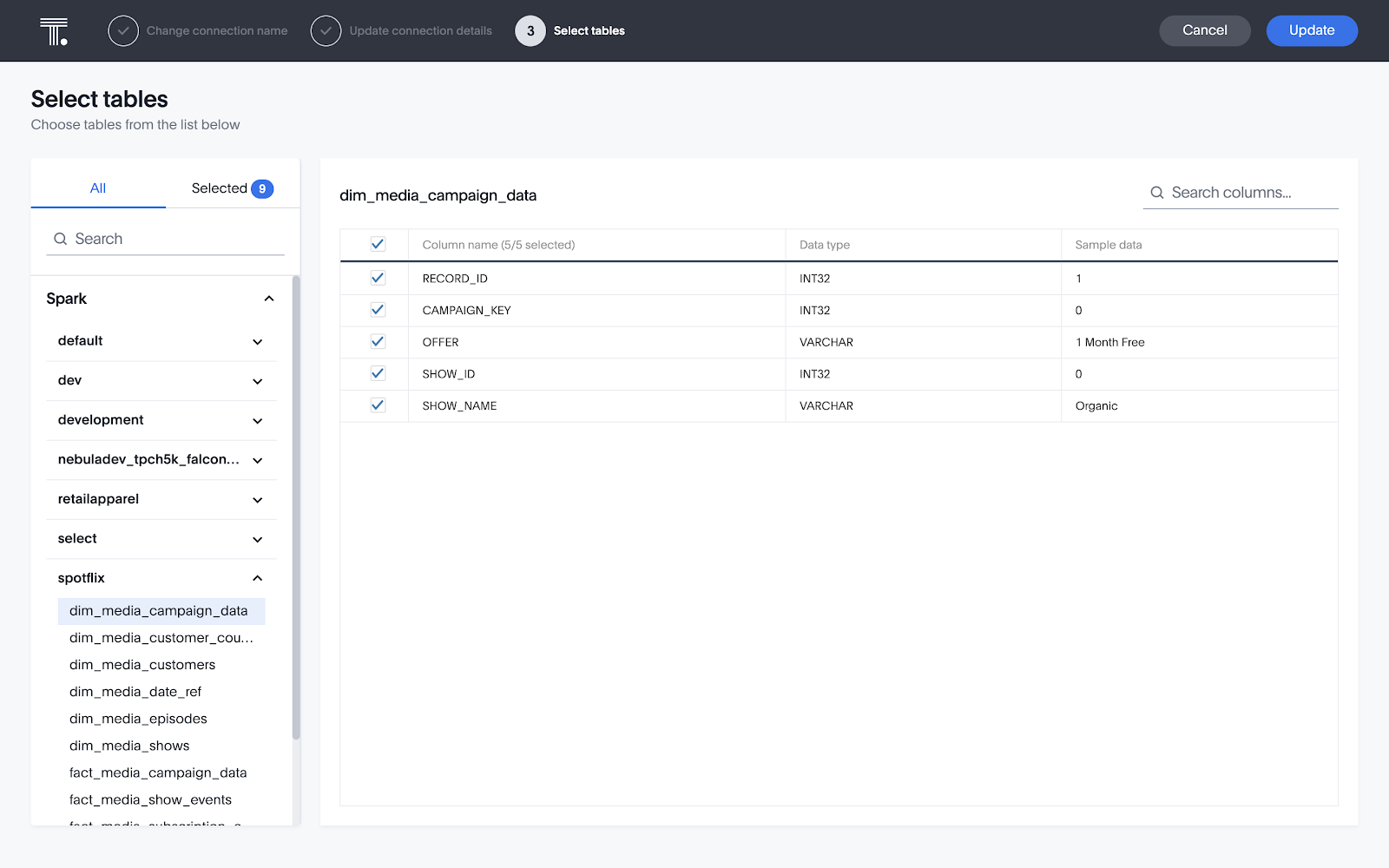
接続情報を入力すると、そのユーザー認証情報でアクセスできるDatabricksインスタンス内のデータベースがすべて表示されます。この接続にテーブルを追加するには、左側のペインでテーブル名をクリックし、1番上のチェックボックスをオンにして、そのテーブル内の列をすべて選択します。列のサブセットを選択することもできますが、ほとんどの場合は、シンプルに各テーブル内の列をすべて含めることをお勧めします。ThoughtSpotは接続内のテーブルを結合するだけなので、1つの接続に各ユースケース用のテーブルをすべて含めることをお勧めします。
<br>ステップ5:ジョインを定義する
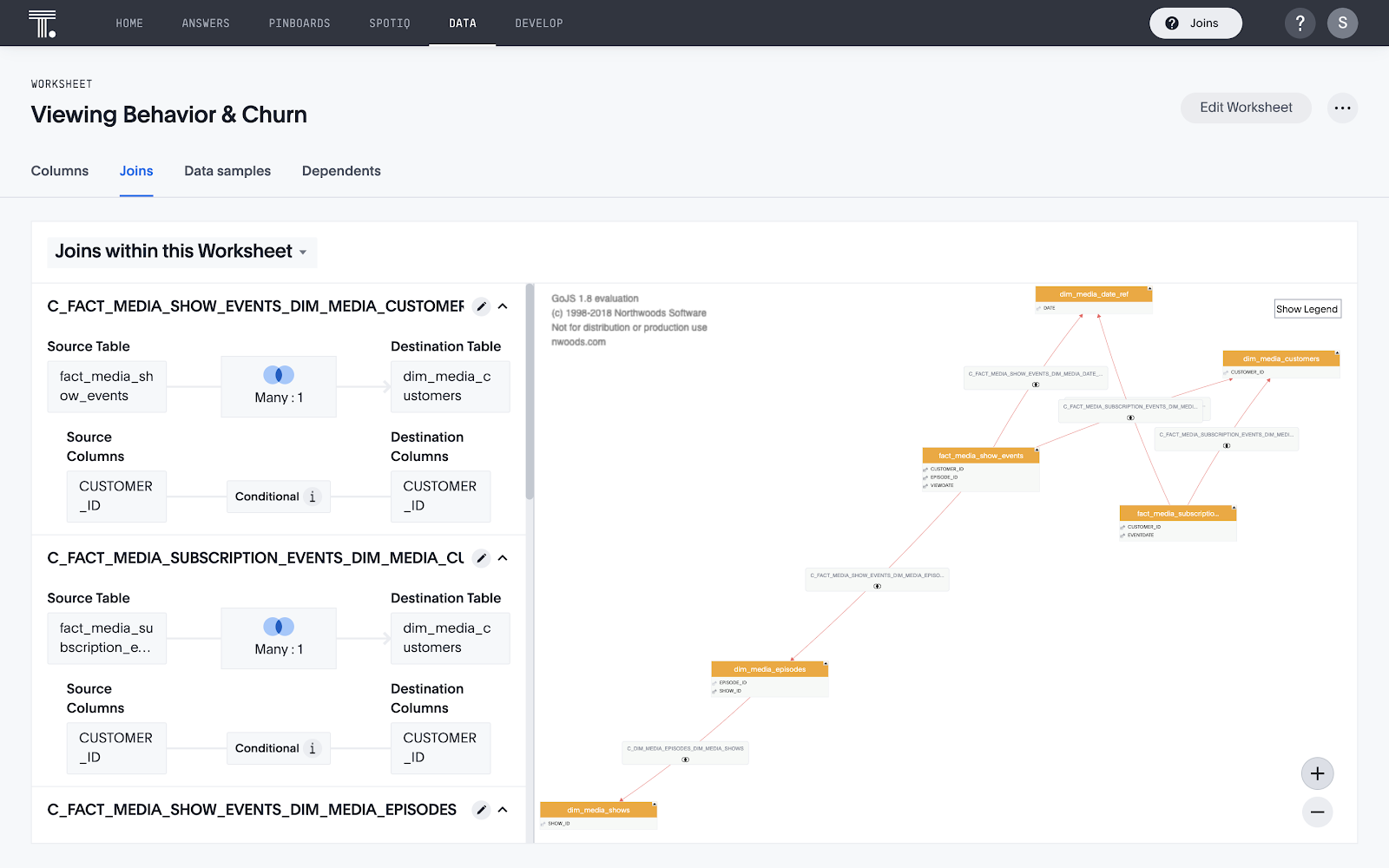
接続を作成したら、ユーザーが複数のテーブルを検索するためのジョインを作成します。接続は複数のデータベースに及ぶことができ、ジョインパスが存在する接続内のテーブルをすべて検索対象に含めることができます。この柔軟性により、複数の主題領域のデータを結合して、すべてのデー/タを対象に分析を行うことができます。
<br>ステップ6:ワークシートを作成する
データモデルが複雑なほど、ビジネスユーザーがそのデータと対話するのが難しくなります。ThoughtSpotのワークシートは、エンドユーザーが複雑なデータにアクセスする方法を簡素化できるパワフルなツールです。ワークシートを利用すれば、ユーザーはテーブルの結合や、データ内の詳細レベルの違いを気にすることなく、複数のテーブルに対して検索を実行できます。また、上級ユーザーはワークシートを使って類義語を挿入したり、高度な計算用の関数を作成したりすることもできます。
<br>データをビジネスユーザーの手に
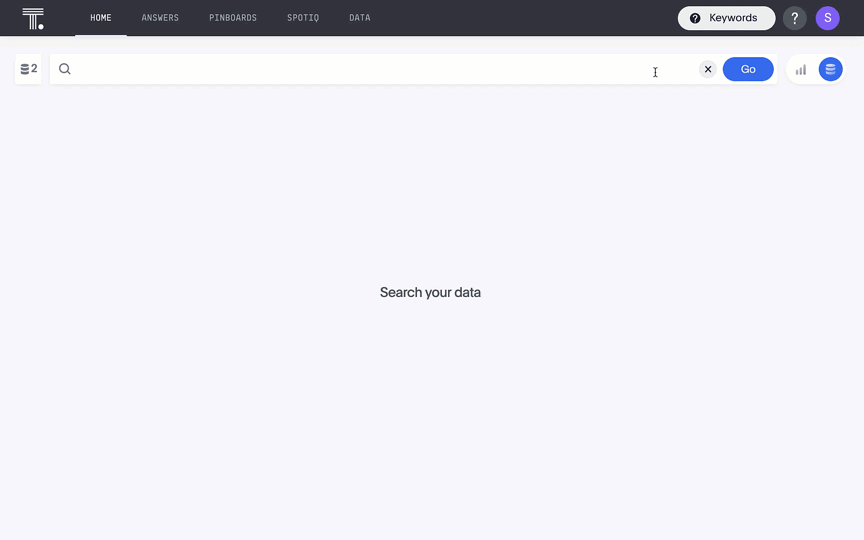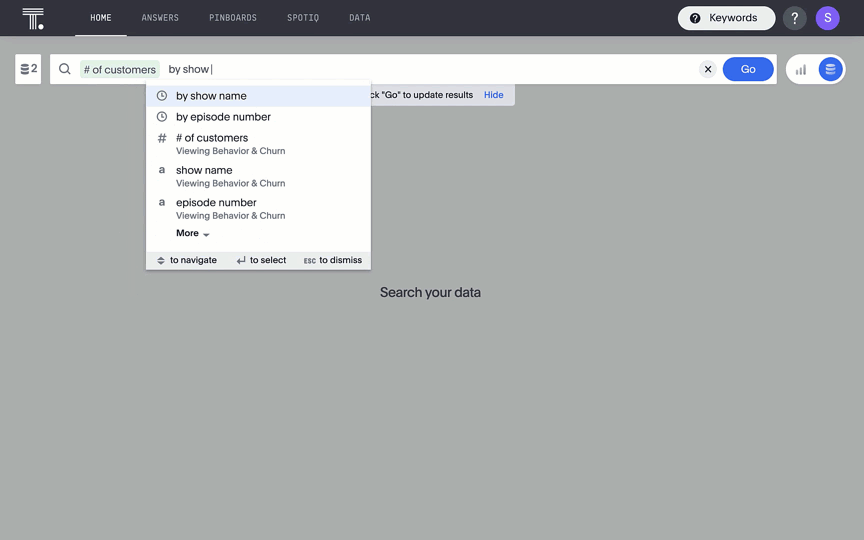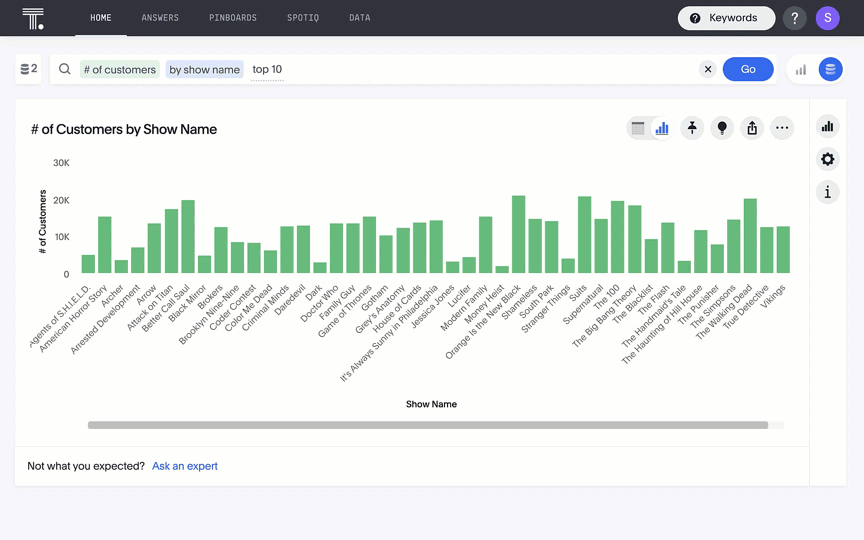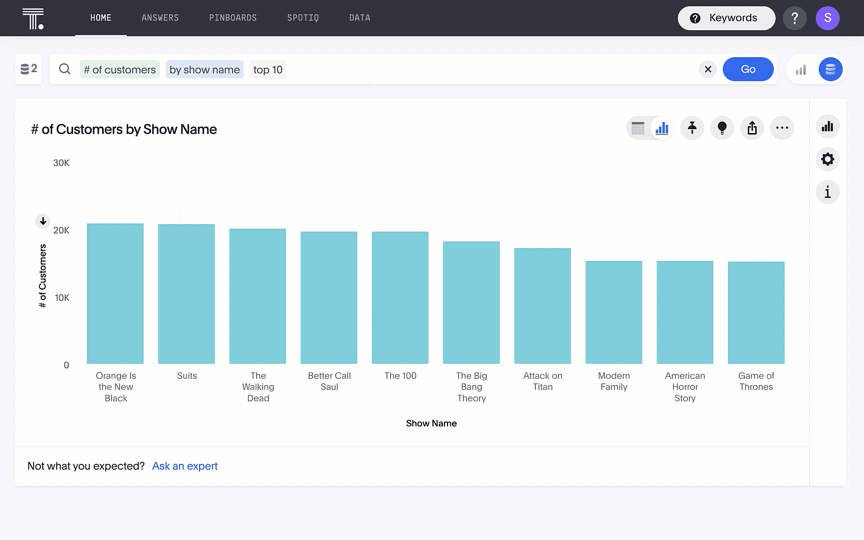
これで、ワークシートをユーザーと共有し、データレイクハウス上にモダンアナリティクスクラウドを展開する準備ができました。ThoughtSpotとDatabricksを組み合わせれば、新たな可能性が開け、新たな方法でデータからインサイトを得ることができます。
ご利用のDatabricksインスタンスでThoughtSpotをお試しになりたい場合は、今すぐThoughSpotまでお問い合せください。





